elasticsearch入门学习笔记,构建java项目es系统入门,es综合基础知识点
发表时间:2022-03-21来源:网络
这是个人elasticsearch入门学习笔记。
内容:
1.elasticsearch的基础认识
2.了解es的基础增删改查
3.倒排索引,分词器简单了解
4.创建映射,添加数据,删除数据,更新数据,ID查询,关键词查询,分词查询,IK分词器,集群结构
5.java操作es,项目配置,jar包导入,定义索引库,java操作es的简单案例
springboot构架es的结构
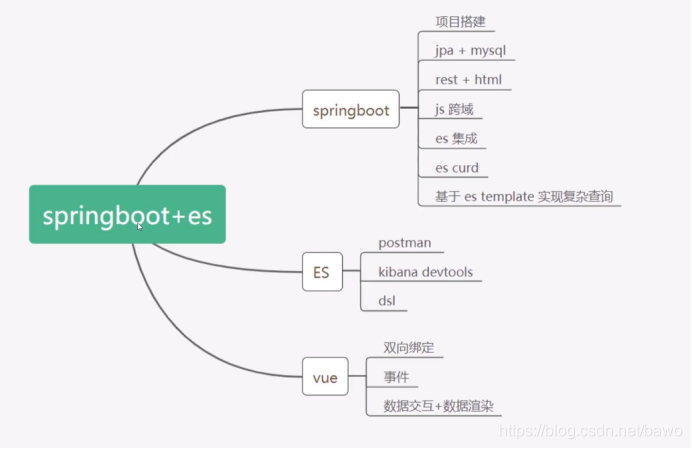
Es和mysql字段对应

关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
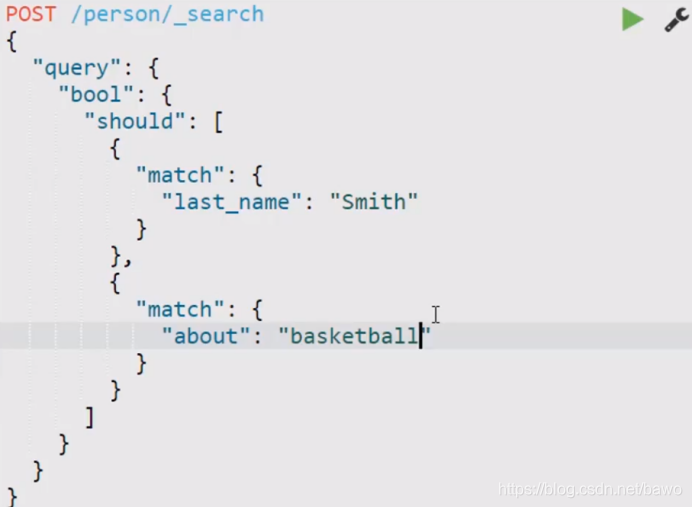
条件参数查询:
倒排索引
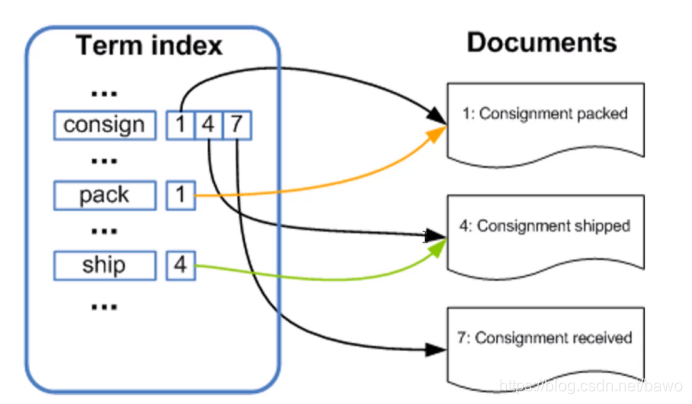
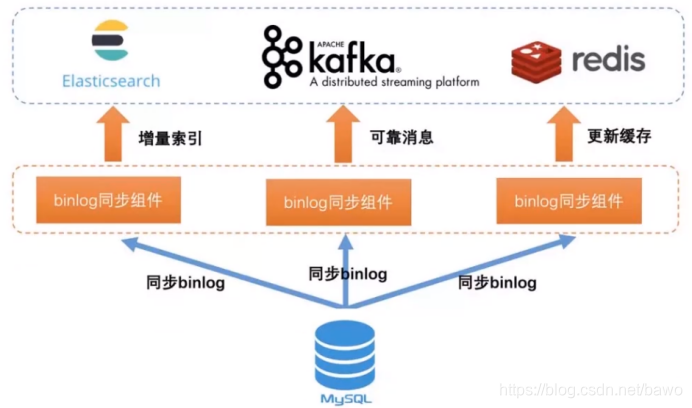
Es官方组件

需要的关键字:
id:Es的ID和mysql的ID要同步
Time:靠时间获取全量和曾量数据同步


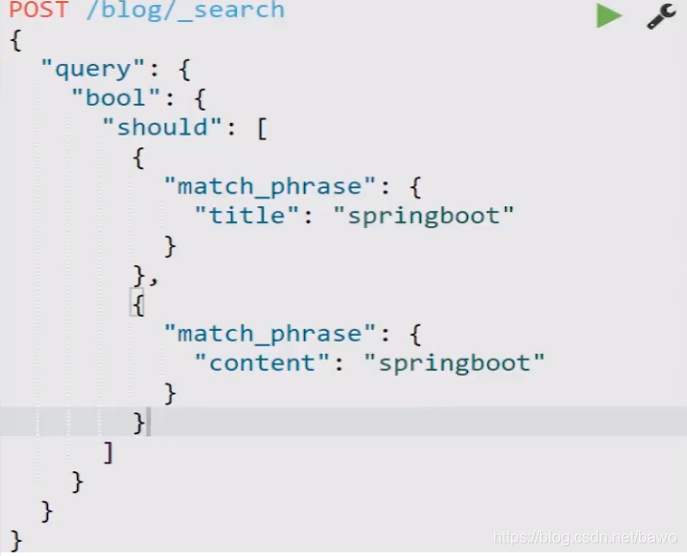
对应的代码

创建映射:
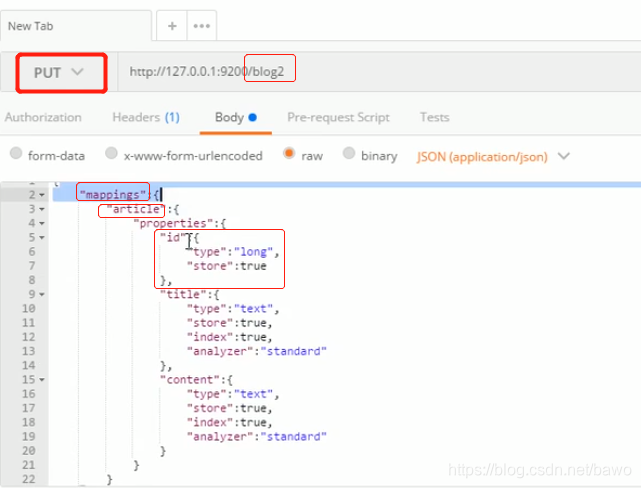
添加文档(数据)

删除:文档
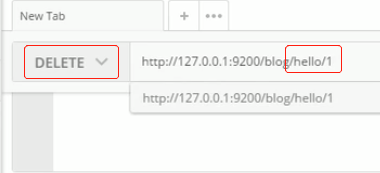
更新:文档,相当于在原来基础上覆盖

查询:
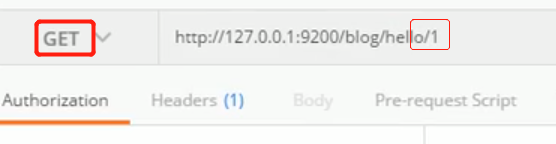
根据ID查询
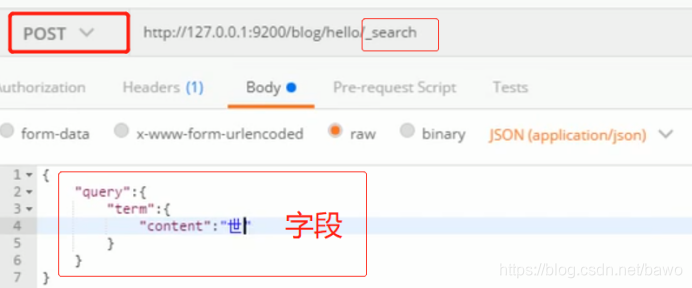
根据关键词查询:查询关键字段
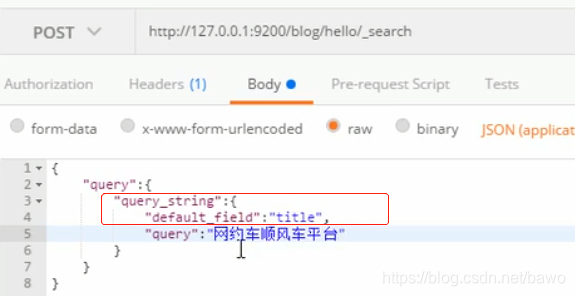
分词查询文档::在哪个域上执行查询,会进行分词
分词器
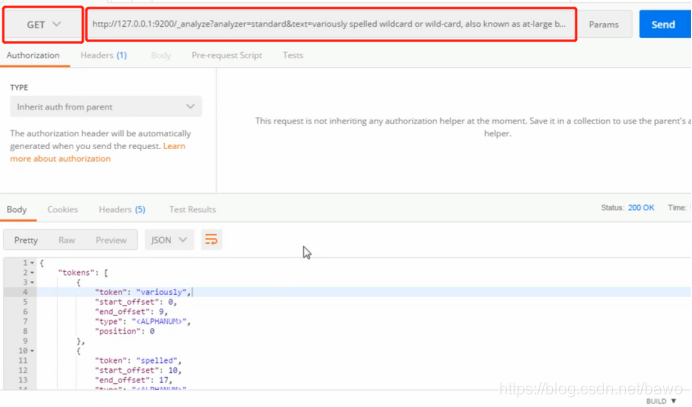
Ik分词器:ik_smart=最小单词为单位,ik_max_word=最大单词为单位,
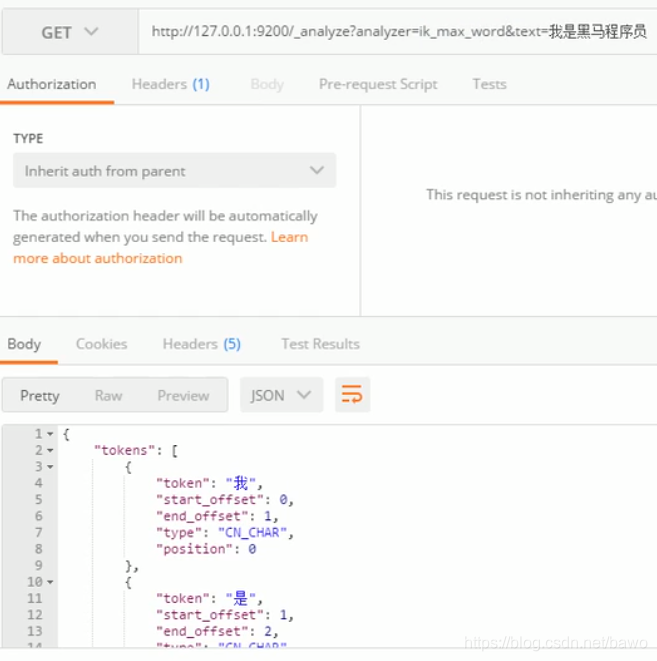
集群:
一个索引库默认五片,组合在一起才是一个完整的索引库,每一片都一个复制节点

一个索引库的物理结构,主索引片和备份片不在一台服务器上,

集群:在一台设备上,建立多个es,把es名字统一,端口名细微改变如,9301,9302,9303等等,这样三台es启动,就自动建立起来了3个集群

java编写es 项目



 定义mapping索引库
定义mapping索引库

Java语法
* must 相当于sql中and
* should 相当于sql中的or
* mustNot 不查xxx
* */
/**Bool bqb = .boolQuery();
bqb.mustNot(.termQuery("houseId", 1));
// 注意.termsQuery和.termQuery两个方法的不同
List itemIds = Lists.newArrayList(1L,2L,3L);
bqb.must(.termsQuery("itemId", itemIds)); // 相当于sql中 item_id in(1,2,3)
bqb.must(.termQuery("skuId","skuId003"));
AggregationBuilders
聚合查询,就是多条件比如分组,归类,统计,最大,最小,平均值

例如要计算每个球队的球员数,如果使用SQL语句,应表达如下:
select team, count(*) as player_count from player group by team;
ES的java api:
1
2
3
TermsBuilder teamAgg= AggregationBuilders.terms("player_count ").field("team");
sbuilder.addAggregation(teamAgg);
SearchResponse response = sbuilder.execute().actionGet();
例如要计算每个球队每个位置的球员数,如果使用SQL语句,应表达如下:
select team, position, count(*) as pos_count from player group by team, position;
ES的java api:
1
2
3
4
TermsBuilder teamAgg= AggregationBuilders.terms("player_count ").field("team");
TermsBuilder posAgg= AggregationBuilders.terms("pos_count").field("position");
sbuilder.addAggregation(teamAgg.subAggregation(posAgg));
SearchResponse response = sbuilder.execute().actionGet();
例如要计算每个球队年龄最大/最小/总/平均的球员年龄,如果使用SQL语句,应表达如下:
select team, max(age) as max_age from player group by team;
ES的java api:
1
2
3
4
TermsBuilder teamAgg= AggregationBuilders.terms("player_count ").field("team");
MaxBuilder ageAgg= AggregationBuilders.max("max_age").field("age");
Sbuilder .addAggregation(teamAgg.subAggregation(ageAgg));//根据团队下的年龄归类
SearchResponse response = sbuilder.execute().actionGet();
例如要计算每个球队球员的平均年龄,同时又要计算总年薪,如果使用SQL语句,应表达如下:
select team, avg(age)as avg_age, sum(salary) as total_salary from player group by team;
ES的java api:
1
2
3
4
5
6
TermsBuilder teamAgg= AggregationBuilders.terms("team");
AvgBuilder ageAgg= AggregationBuilders.avg("avg_age").field("age");
SumBuilder salaryAgg= AggregationBuilders.avg("total_salary ").field("salary");
sbuilder.addAggregation(teamAgg.subAggregation(ageAgg).subAggregation(salaryAgg));
SearchResponse response = sbuilder.execute().actionGet();
例如要计算每个球队总年薪,并按照总年薪倒序排列,如果使用SQL语句,应表达如下:
select team, sum(salary) as total_salary from player group by team order by total_salary desc;
ES的java api:
1
2
3
4
TermsBuilder teamAgg= AggregationBuilders.terms("team").order(Order.aggregation("total_salary ", false);
SumBuilder salaryAgg= AggregationBuilders.avg("total_salary ").field("salary");
sbuilder.addAggregation(teamAgg.subAggregation(salaryAgg));
SearchResponse response = sbuilder.execute().actionGet();
默认情况下,search执行后,仅返回10条聚合结果,如果想反悔更多的结果,需要在构建TermsBuilder 时指定size:
TermsBuilder teamAgg= AggregationBuilders.terms("team").size(15);
Aggregation结果的解析/输出
得到response后:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Map aggMap = response.getAggregations().asMap();
StringTerms teamAgg= (StringTerms) aggMap.get("keywordAgg");
Iterator teamBucketIt = teamAgg.getBuckets().iterator();
while (teamBucketIt .hasNext()) {
Bucket buck = teamBucketIt .next();
//球队名
String team = buck.getKey();
//记录数
long count = buck.getDocCount();
//得到所有子聚合
Map subaggmap = buck.getAggregations().asMap();
//avg值获取方法
double avg_age= ((InternalAvg) subaggmap.get("avg_age")).getValue();
//sum值获取方法
double total_salary = ((InternalSum) subaggmap.get("total_salary")).getValue();
//...
//max/min以此类推
}
(1)统计某个字段的数量ValueCountBuilder vcb= AggregationBuilders.count("count_uid").field("uid");(2)去重统计某个字段的数量(有少量误差)CardinalityBuilder cb= AggregationBuilders.cardinality("distinct_count_uid").field("uid");(3)聚合过滤FilterAggregationBuilder fab= AggregationBuilders.filter("uid_filter").filter(.("uid:001"));(4)按某个字段分组TermsBuilder tb= AggregationBuilders.terms("group_name").field("name");(5)求和SumBuilder sumBuilder= AggregationBuilders.sum("sum_price").field("price");(6)求平均AvgBuilder ab= AggregationBuilders.avg("avg_price").field("price");(7)求最大值MaxBuilder mb= AggregationBuilders.max("max_price").field("price");(8)求最小MinBuilder min= AggregationBuilders.min("min_price").field("price");(9)按日期间隔分组DateHistogramBuilder dhb= AggregationBuilders.dateHistogram("dh").field("date");(10)获取聚合里面的结果TopHitsBuilder thb= AggregationBuilders.topHits("top_result");(11)嵌套的聚合NestedBuilder nb= AggregationBuilders.nested("negsted_path").path("quests");(12)反转嵌套AggregationBuilders.reverseNested("res_negsted").path("kps ");
知识阅读





软件推荐
更多 >-
 查看
查看皓盘云建最新版下载v9.0 安卓版
53.38MB |商务办公
-
 查看
查看ris云客移动销售系统最新版下载v1.1.25 安卓手机版
42.71M |商务办公
-
 查看
查看粤语翻译帮app下载v1.1.1 安卓版
60.01MB |生活服务
-
 查看
查看人生笔记app官方版下载v1.19.4 安卓版
125.88MB |系统工具
-
 查看
查看萝卜笔记app下载v1.1.6 安卓版
46.29MB |生活服务
-
 查看
查看贯联商户端app下载v6.1.8 安卓版
12.54MB |商务办公
-
 查看
查看jotmo笔记app下载v2.30.0 安卓版
50.06MB |系统工具
-
 查看
查看鑫钜出行共享汽车app下载v1.5.2
44.7M |生活服务
精选栏目
热门推荐


-
1
 联想笔记本电脑清理灰尘详细步骤
联想笔记本电脑清理灰尘详细步骤2022-03-26
-
2
 神舟bios设置图解教程
神舟bios设置图解教程2022-03-26
-
3
 联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议
联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议2022-03-26
-
4
 ACPI是什么?BIOS中怎么设置ACPI?
ACPI是什么?BIOS中怎么设置ACPI?2022-03-26
-
5
 联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程
联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程2022-03-26
-
6
 联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)
联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)2022-03-26
-
7
 鸿蒙系统能安装vscode吗
鸿蒙系统能安装vscode吗2022-03-26
-
8
 192.168.1.62登录入口管理网址
192.168.1.62登录入口管理网址2022-03-26
-
9
 fast路由器设置网址192.168.1.1,falogin.cn密码
fast路由器设置网址192.168.1.1,falogin.cn密码2022-02-15
-
10
 联想笔记本装系统怎么进入PE图文教程
联想笔记本装系统怎么进入PE图文教程2022-02-14





-
1

-
2
机器人战斗竞技场手机版下载v3.71 安卓版
其它手游 -
3
果冻人大乱斗最新版下载v1.1.0 安卓版
其它手游 -
4
王者100刀最新版下载v1.2 安卓版
其它手游 -
5
trueskate真实滑板正版下载v1.5.102 安卓版
其它手游 -
6
矢量跑酷2最新版下载v1.2.1 安卓版
其它手游 -
7
休闲解压合集下载v1.0.0 安卓版
其它手游 -
8
指尖游戏大师最新版下载v4.0.0 安卓版
其它手游 -
9
飞天萌猫下载v3.0.3 安卓版
其它手游 -
10
火柴人越狱大逃脱下载v1.1 安卓版
其它手游