如何提高写代码的水平?
发表时间:2022-03-25来源:网络
本人凝聚态物理专业,读博期间没干别的,就多写了些算法。CS专业的同学请移步,因为在下完全是外行。本文面向科研工作者,工作中多多少少需要代码能力,却可强可弱的,给大家一些提高工作效率的实用建议,不限于算法能力。大体内容目录如下:
1 算法结构:
1.1 算法接口运用
1.2 算法重构的基本出发点
1.3 使用库vs自己实现
2 基础知识
基础知识与二八原则
1 算法结构:
1.1 算法接口运用
下面以简单画图算法举例:
比如要用如下数据的第一列和第三列画图:
iter_num candidate accurate failed 120 3.235294 92.450980 4.313725 121 1.209495 96.691623 2.098882 122 4.120085 95.417709 0.462206 123 1.089119 96.877096 2.033786 124 2.010693 97.565817 0.423490 125 1.404169 98.328175 0.267657 126 2.901615 96.115505 0.982880可以用以下代码段1:
import numpy as np import os import sys import matplotlib.pyplot as plt ### Read me: ### command line set variables: filename, column number for fig x, y filename=sys.argv[1] cnum1=sys.argv[2] cnum2=sys.argv[3] listnum=np.stack(np.loadtxt(filename,dtype='float', skiprows=1)) #入读文件,忽略第一行 x=listnum[:,int(cnum1)] y=listnum[:,int(cnum2)] plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' plt.scatter( x, y, color='blue', marker='o', s=8.0) plt.plot( x, y, color='grey', linewidth='1.0', linestyle='-') plt.xlabel('Iter number') plt.ylabel('Distribution') plt.title('DP Model accuracy') #plt.legend() plt.show() plt.savefig("accuracy.png")执行python plot.py a.dat 0 2 效果如下图
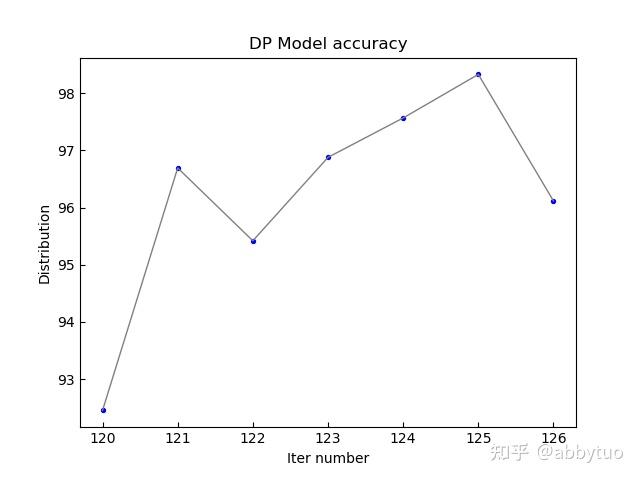 a.dat数据效果图
a.dat数据效果图这段代码当然很好用。但是它有一个明显的缺点,所有的输入输出都是写死的,没有交互接口。比如你想跳过文件首的两行,就得通过修改代码listnum=np.stack(np.loadtxt(filename,dtype='float', skiprows=2)) 来实现。
问题出在哪里呢?出在代码的接口位置:
filename=sys.argv[1] cnum1=sys.argv[2] cnum2=sys.argv[3]sys.argv 是很方便的终端输入模块,但不是一种可交互的模块。一个可能的替代选择是argparse 。比如以上代码可以如此修改:
import numpy as np import os import sys import matplotlib.pyplot as plt import argparse parser = argparse.ArgumentParser(description='Figure texts') parser.add_argument('--title', type=str, default='', help='titile of the figure') parser.add_argument('--skiprows', type=int, default=0, help="skip rows") parser.add_argument('--line_y', type=int, default=1, help="line of y") parser.add_argument('--line_x', type=int, default=0, help="line of x") parser.add_argument('--xlabel', type=str, default="x", help="xlabel") parser.add_argument('--ylabel', type=str, default="y", help="ylabel") parser.add_argument('INPUT', type=str, nargs = "+", help="input file") args = parser.parse_args() filename = args.INPUT cnum1 = args.line_x cnum2 = args.line_y skiprows = args.skiprows listnum=np.stack(np.loadtxt(filename,dtype='float', skiprows=1)) #入读文件,忽略第一行 x=listnum[:,int(cnum1)] y=listnum[:,int(cnum2)] plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' plt.scatter( x, y, color='blue', marker='o', s=8.0) plt.plot( x, y, color='grey', linewidth='1.0', linestyle='-') plt.xlabel('Iter number') plt.ylabel('Distribution') plt.title('DP Model accuracy') #plt.legend() plt.show() plt.savefig("accuracy.png")执行如下命令python plot.py a.dat --skiprows=1 --line_x=0 --line_y=2。
1.2 算法重构的基本出发点
仍以以上算法为例,这段算法有一个问题,所有的功能指令都”按顺序罗列“。这段算法实现的功能主要分为四类:输入参数;读取输入文件;设置图片格式;保存。
但这段算法存在一个问题,每当我们想要实现的功能稍微有变,算法都面临大幅修改。比如,如果我们想从多个文件读入数据进行画图,比如两次运行的数据画在同一张图上做对比,算法就得做如下修改为代码段3:
import numpy as np import os import sys import matplotlib.pyplot as plt import argparse ### Read me: ### command line set variables: filename, column number for fig x, y #filename=sys.argv[1] #cnum1=sys.argv[2] #cnum2=sys.argv[3] parser = argparse.ArgumentParser(description='Figure texts') parser.add_argument('--title', type=str, default='', help='titile of the figure') parser.add_argument('--skiprows', type=int, default=0, help="skip rows") parser.add_argument('--line_y', type=int, default=1, help="line of y") parser.add_argument('--line_x', type=int, default=0, help="line of x") parser.add_argument('--xlabel', type=str, default="x", help="xlabel") parser.add_argument('--ylabel', type=str, default="y", help="ylabel") parser.add_argument('INPUT', type=str, nargs = "+", help="input file") args = parser.parse_args() filename = args.INPUT cnum1 = args.line_x cnum2 = args.line_y skiprows = args.skiprows for f in filename: listnum=np.stack(np.loadtxt(f,dtype='float', skiprows=skiprows)) #入读文件,忽略第一行 x=listnum[:,int(cnum1)] y=listnum[:,int(cnum2)] plt.scatter( x, y, color='blue', marker='o', s=8.0) plt.plot( x, y, color='grey', linewidth='1.0', linestyle='-') plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' plt.xlabel('Iter number') plt.ylabel('Distribution') plt.title('DP Model accuracy') #plt.legend() plt.show() plt.savefig("accuracy.png")其中,为了能多文件画图,我们将格式设置部分全都集中到了画图之后,并把所有画图操作归入for 循环内。
在代码段3中,上述四类操作依然”按顺序罗列“,但是功能按类别发生了明显的分块。此时,如果我们预期算法将来可能要实现更多功能,就需要对算法进行最简单的一种重构:将功能变成函数。如下代码段4:
import numpy as np import os import sys import matplotlib.pyplot as plt import argparse def plotlist(listnum, cnum1, cnum2): x=listnum[:,int(cnum1)] y=listnum[:,int(cnum2)] plt.scatter( x, y, color='blue', marker='o', s=8.0) plt.plot( x, y, color='grey', linewidth='1.0', linestyle='-') def setformat(xlabel, ylabel, title): plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' plt.xlabel(xlabel) plt.ylabel(ylabel) plt.title(title) def save(): plt.show() plt.savefig("accuracy.png") if __name__ == "__main__": parser = argparse.ArgumentParser(description='Figure texts') parser.add_argument('--title', type=str, default='', help='titile of the figure') parser.add_argument('--skiprows', type=int, default=0, help="skip rows") parser.add_argument('--line_y', type=int, default=1, help="line of y") parser.add_argument('--line_x', type=int, default=0, help="line of x") parser.add_argument('--xlabel', type=str, default="x", help="xlabel") parser.add_argument('--ylabel', type=str, default="y", help="ylabel") parser.add_argument('INPUT', type=str, nargs = "+", help="input file") args = parser.parse_args() filename = args.INPUT cnum1 = args.line_x cnum2 = args.line_y skiprows = args.skiprows for f in filename: listnum=np.stack(np.loadtxt(f,dtype='float', skiprows=skiprows)) #入读文件,忽略第一行 plotlist(listnum, cnum1, cnum2) setformat(args.xlabel, args.ylabel, args.title)与代码段3相比,这段算法似乎没做什么事情,只是把不同的功能分别归到了函数里。但这段算法有一个最明显的优势,即主函数的可读性更强。除输入接口外,算法执行部分的功能很集中,一目了然:load文件中的数据,画图,设置图片格式。
以上是最最简单的算法重构,只为揭示算法重构的思想。那么什么时候需要进行算法重构呢?一般出于以下两个需求:
提高算法可读性方便扩展当你预期算法将需要实现更多功能,面临更多修改时,立马重构。重构可能会花去你一整天甚至几周的工作量,但是它能提升将来的效率,并扩大发展空间,带来的收益绝对是值得的。
1.3 使用库和自己实现
在以上算法实现中,我们主要用到三个库,numpy:用来load文件数据;matplotlib:用来画图;argparse:用来接收命令行输入参数。
python有很多库,可以用来实现各种功能。在学习这些库的过程中,私以为主要有两条经验可以分享:
学会读官方文档不要只用库。权为锻炼也好,自己从零开始,不引用任何库,实现一些功能关于第一条,有两点需要强调:
1. 以官方文档为准,如果官方文档有不懂的地方,再去搜索其他帖子,与官方文档比照着看
2. 请看下图1 的目录部分,每一个模块的文档会先对模块本身做一个简单介绍,接下来是模块中包含的函数,每一个函数都有相应的说明(参见下图2)。模块中函数的调用方式为,在python文件首import,并在文件中引用。
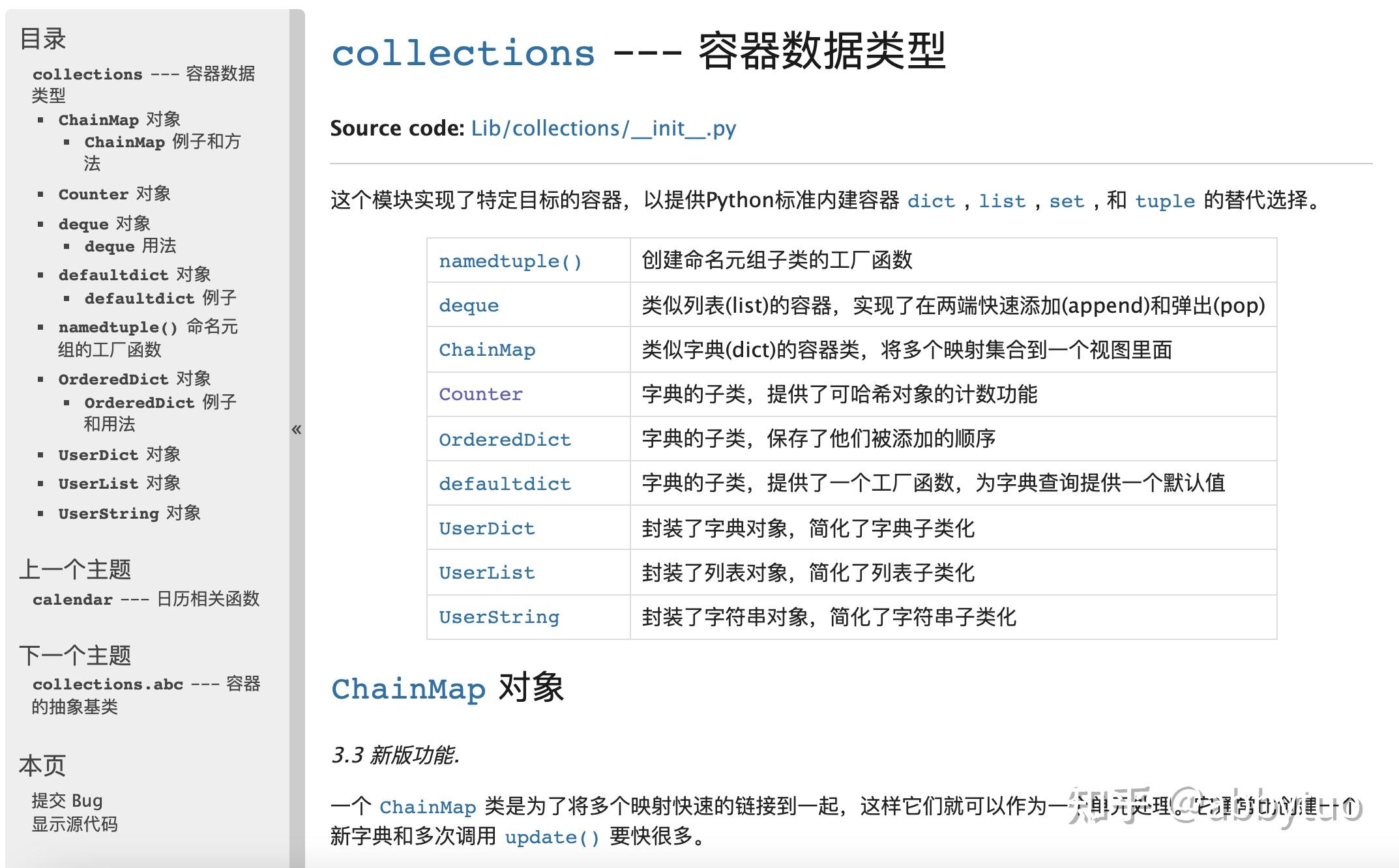

为什么会提第二条,因为小编出自物理专业,同事、同学、相识大多都是数理化专业,却发现许多人(包括小编自己偶尔)忘记了一些非常基本的数学计算,比如如何求矢量模,如何求六面体的体积,等等。所以,当你发现自己懒得去谷歌或百度查找有什么库可以实现你想要的功能,不要忙于问人,干脆自己写一个。数学公式一定要常推,否则数理能力会一并退化。
因此,附加本文的第二部分,关于基础知识和二八原则。
基础知识
基础知识与二八原则
以一个举例开头,有一天,小编发现自己不知道4_3螺旋轴是什么意思了。小编知道它是一种对称操作,但是翻了几本还能找到的群论书,发现自己手边能找到的书里都没有对这种基本概念的解释。这时候,去问了别人。但是在别人详细解释了4_3螺旋轴是什么意思之后,小编没有止步于此,而是一并让别人推荐了一本群论书,和北大冯骥老师的授课笔记。
小编的工作是计算物理,最常用到的软件包括VASP和LAMMPS等等。VASP软件的输出OUTCAR是标准格式的,里边提供了大量信息。这造成许多计算理化材料专业同学的懒惰,比如结构文件POSCAR中只给出了晶格常数,那么由晶格常数怎么得出体积呢?OUTCAR里有。慢慢地,小编发现很多同学已经忘记了已知晶格常数如何求晶胞的体积,忘记是正常的,更糟的是,有的同学完全不知道这个知识在哪本书里有,或者属于哪一学科。
上述两个例子,是为了提出本章的第一个问题:知识图谱的重要性。建立知识图谱,你可以忘记已知晶格常数如何求体积,这不用惊慌,回顾一下就好,但是如果你发现自己完全想不起来去哪里查询这一知识,就是该惊慌的时候了。(PS:固体物理)
但是,大家都会说,现在的知识这么多,信息泛滥,怎么可能什么都学会呢?人们越来越发现自己忘得比学得还快,马上就要被人工智能取代。这就引出本章的第二个主题:二八原则。
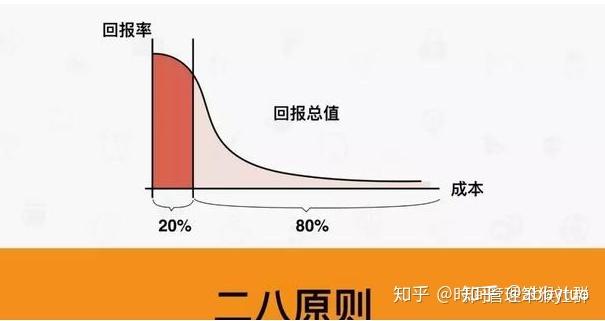
二八原则
以下引自知乎作者:时间管理笨猴社群
巴列特定律:“总结果的80%是由总消耗时间中的20%所形成的。” 按事情的“重要程度”编排事务优先次序的准则是建立在“重要的少数与琐碎的多数”的原理的基础上。
举例说明:
80%的销售额是源自20%的顾客;
80%的电话是来自20%的朋友;
80%的总产量来自20%的产品;
80%的财富集中在20%的人手中;
链接:https://www.zhihu.com//303497605/answer/1098996098
来源:知乎
著作权归作者所有。
二八原则强调了一个要点,一个人的学习时间必须占到总工作时间的百分之八十。这里的学习不只包括掌握技能,更重要的是系统性学习。那么什么是掌握技能,什么是系统性学习呢?
比如:你不知道怎么用Python画图,你通过问别人,得知matplotlib可以画图,你通过谷歌或百度学到怎么用matplotlib画图。这是掌握技能。
很多人工作之后,发现自己不再有时间和动力去系统性学习,而是不断地掌握越来越多的技能。这是不够的。系统性学习才能让人变成专家。
比如:小编专业计算物理,用得比较多的软件包括VASP和LAMMPS。当小编用LAMMPS里某个系综,比如:
fix 1 all npt temp ${TEMP} ${TEMP} ${TAU_T} iso ${PRES} ${PRES} ${TAU_P}
这一设置可能从别人的设置抄来。但是小编在修改这一文件之前,
要通读一遍LAMMPS说明书里fix npt的所有说明(LAMMPS里的关键词直接谷歌搜索,非常方便)在说明中发现的重要相关说明,比如在fix npt的说明处,你会发现对LAMMPS结构文件中所使用的晶格参量的说明。学习说明中涉及的系综。如果这一系综正好是自己要用的,一定要找到一本统计力学书,找到相关部分,把理论看一遍,公式推导一遍。如上所述,再怎么强调也不为过,数学公式一定要常推,否则数理能力会一并退化。如果你是数理专业从业者,自己手边一定要常备一本和自己目前工作强相关的基础理论书。比如:
如果你发现工作中要用到群论,而自己以前完全没学过。找一本你能看懂的,保证自己以一定的进度学习这本书。
如果你发现自己以前学过群论,而有一些基础知识已经忘记,买一本群论,放在家里或办公桌上,翻阅复习。
以下为题外话:
如果你发现自己在学习、工作或生活中面临瓶颈,而且是极大的瓶颈,分析:
我能突破这一瓶颈吗?需要付出的代价是什么?
如果代价很大,能不能找到一条路绕过?避开瓶颈,发挥自己的优势。
如果不能,适时地想起二八原则,走最不寻常的路,跨过最艰难的障碍。
一个人的学习时间必须占到总工作时间的百分之八十。日自省,静夜思。
上一篇:如何编写无法维护的代码
下一篇:代码写好后如何运行
知识阅读





软件推荐
更多 >-
 查看
查看皓盘云建最新版下载v9.0 安卓版
53.38MB |商务办公
-
 查看
查看ris云客移动销售系统最新版下载v1.1.25 安卓手机版
42.71M |商务办公
-
 查看
查看粤语翻译帮app下载v1.1.1 安卓版
60.01MB |生活服务
-
 查看
查看人生笔记app官方版下载v1.19.4 安卓版
125.88MB |系统工具
-
 查看
查看萝卜笔记app下载v1.1.6 安卓版
46.29MB |生活服务
-
 查看
查看贯联商户端app下载v6.1.8 安卓版
12.54MB |商务办公
-
 查看
查看jotmo笔记app下载v2.30.0 安卓版
50.06MB |系统工具
-
 查看
查看鑫钜出行共享汽车app下载v1.5.2
44.7M |生活服务
精选栏目
热门推荐


-
1
 联想笔记本电脑清理灰尘详细步骤
联想笔记本电脑清理灰尘详细步骤2022-03-26
-
2
 神舟bios设置图解教程
神舟bios设置图解教程2022-03-26
-
3
 联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议
联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议2022-03-26
-
4
 ACPI是什么?BIOS中怎么设置ACPI?
ACPI是什么?BIOS中怎么设置ACPI?2022-03-26
-
5
 联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程
联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程2022-03-26
-
6
 联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)
联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)2022-03-26
-
7
 鸿蒙系统能安装vscode吗
鸿蒙系统能安装vscode吗2022-03-26
-
8
 192.168.1.62登录入口管理网址
192.168.1.62登录入口管理网址2022-03-26
-
9
 fast路由器设置网址192.168.1.1,falogin.cn密码
fast路由器设置网址192.168.1.1,falogin.cn密码2022-02-15
-
10
 联想笔记本装系统怎么进入PE图文教程
联想笔记本装系统怎么进入PE图文教程2022-02-14





-
1

-
2
机器人战斗竞技场手机版下载v3.71 安卓版
其它手游 -
3
果冻人大乱斗最新版下载v1.1.0 安卓版
其它手游 -
4
王者100刀最新版下载v1.2 安卓版
其它手游 -
5
trueskate真实滑板正版下载v1.5.102 安卓版
其它手游 -
6
矢量跑酷2最新版下载v1.2.1 安卓版
其它手游 -
7
休闲解压合集下载v1.0.0 安卓版
其它手游 -
8
指尖游戏大师最新版下载v4.0.0 安卓版
其它手游 -
9
飞天萌猫下载v3.0.3 安卓版
其它手游 -
10
火柴人越狱大逃脱下载v1.1 安卓版
其它手游