LeetCode按照怎样的顺序来刷题比较好?
发表时间:2022-03-25来源:网络
大学刷题怪,本科毕业拿到BAT 各大互联网公司 Offer,这题我太有回答权了!!!
大学的时候没事干就是刷 Leetcode,尤其是校招前那段时间,刷遍了Leetcode 常见的题型,大概刷了近六百来道:
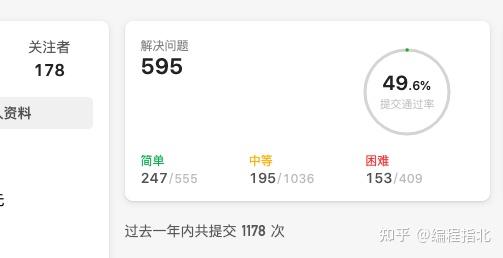
不知道多少人刷 Leetcode 永远停在了 Two Sum,到现在我才明白力扣(LeetCode)刷题顺序真的很重要!!!
不然的话,对于小白可能会有比较强烈的挫败感!
LeetCode题目实在太多了,从最初几百道到现在上千道,我们没有必要全刷,题永远是刷不完的,但是这些解题所需要的知识其实是变化不大的。
所以在刷题的时候一定要刷经典题,要举一反三,从一类题抽象出共通的解法,才能以不变应万变,这才是刷题的本质,而不是单单为了刷题而刷题。
首先,刷题之前送大家一本谷歌大佬总结的刷题笔记,上面分类汇总了上百道经典题型和题解,看完秒杀中等难度的 Leetcode 应该不成问题:

接下来,手把手教大家如何正确打开 Leetcode!全程干货,注意收藏点赞(双击屏幕~~)哈(适合算法一般的同学,ACM大佬赶紧退散)
一、刷题前
首先,大家要明白一个点,那就是我们刷题不是为了去刷题,刷题的目的是为了巩固数据结构与算法,那么也就是说刷题前我们就要学完一遍常见的数据结构与算法,不然你去巩固啥呢?是吧
在这里我就要强调数据结构如何学习了。
首先要明白,不管是数组、树、堆还是啥,最终对应在内存中的存储方式只有两种:
数组(顺序存储)链表(链式存储)数组由于是紧凑连续存储,可以随机访问,通过索引快速找到对应元素,而且相对节约存储空间。但正因为连续存储,内存空间必须一次性分配够,所 以说数组如果要扩容,需要重新分配一块更大的空间,再把数据全部复制过 去,时间复杂度 O(N);而且你如果想在数组中间进行插入和删除,每次必 须搬移后面的所有数据以保持连续,时间复杂度 O(N)。
链表因为元素不连续,而是靠指针指向下一个元素的位置,所以不存在数组 的扩容问题;如果知道某一元素的前驱和后驱,操作指针即可删除该元素或 者插入新元素,时间复杂度 O(1)。但是正因为存储空间不连续,你无法根 据一个索引算出对应元素的地址,所以不能随机访问;而且由于每个元素必 须存储指向前后元素位置的指针,会消耗相对更多的储存空间。
那么基于这两种最基本的数据结构我们就可以构建:
线性表:队列(FIFO)、栈:https://www.cnblogs.com/skywang12345/p/3561803.html
https://www.cnblogs.com/skywang12345/p/3576328.html
堆:二叉堆、左倾堆、二项堆:https://www.cnblogs.com/skywang12345/p/3610187.html
图:有向图、无向图https://www.cnblogs.com/skywang12345/p/3707597.html
常见算法:
https://www.cnblogs.com/skywang12345/p/3711483.html
八大排序:冒泡、快速排序、插入排序、希尔排序、选择排序、堆排序、归并排序、桶排序、基数排序暴力枚举法分治法递归动态规划贪心....推荐大家学习这些数据结构和算法可以看看《算法4》这本书,这本书比较适合初学者,算法讲解也比较清晰易懂且全面。
这本书看起来挺厚的,但是前面几十⻚是教你 Java 的;每章后面还有习 题,占了不少⻚数;每章还有一些数学证明,这些都可以忽略。这样算下 来,剩下的就是基础知识和疑难解答之类的内容,含金量很高,把这些基础 知识动手实践一遍,真的就可以达到不错的水平了。

这本书在豆瓣的评价也很高,一个是因为讲解详细,还有大量配图,另一个原因就是书中把一些算法和现实生活中的使用场景联系起来,你不仅知道某个算法怎么实现,也知道它大概能运用到什么场景。
这些经典的算法学习书,我都汇总了,有需要的同学可以看下这里下载:
书单:
或者去这个 Github 开源仓库,基本包含了常见的 CS 编程学习书籍,可以 star 一下,需要的时候直接去上面找书:
二、刷题,起航!
刷题之前,我们需要知道怎么去刷,按什么顺序刷题,应该根据需求来:
如果是为了拿大厂offer,那么在LeetCode上刷够大概 200 道经典题就差不多了,注意不是重复刷简单题,是分门别类的刷,具体的下文会讲到;如果是想长期系统的学习算法,提升自己的学科素养,建议按类型刷题,分门别类的学习、总结,有针对性的提升;下面列一些典型的题型吧:
1. 线性表:
1.1 Remove Duplicates from Sorted Array
1.2 Remove Duplicates from Sorted Array II
1.3 Search in Rotated Sorted Array II
1.4 Median of Two Sorted Arrays
1.5 Longest Consecutive Sequence
1.6 Two Sum
1.7 Valid Sudoku
1.8 Trapping Rain Water
1.9 Swap Nodes in Pairs
1.10 Reverse Nodes in k-Group
2. 字符串
2.1 Valid Palindrome
2.2 Implement strStr()
3.3 String to Integer (atoi)
3.4 Add Binary
3.5 Longest Palindromic Substring
3.6 Regular Expression Matching
3.7 Wildcard Matching
3.8 Longest Common Prefix
3.9 Valid Number
3.10 Integer to Roman
3. 树、二叉树
3.1 Binary Tree Preorder Traversal
3.2 Binary Tree Inorder Traversal
3.3 Binary Tree Postorder Traversal
3.4 Binary Tree Level Order Traversal II
3.5 Binary Tree Zigzag Level Order Traversal
3.6 Construct Binary Tree from Preorder and Inorder Traversal
3.7 Unique Binary Search Trees
3.8 Validate Binary Search Tree
3.9 Convert Sorted Array to Binary Search Tree
4. 排序
4.1 Merge Sorted Array
4.2 Merge Two Sorted Lists
4.3 Merge k Sorted Lists
4.4 Insertion Sort List
4.5 Sort List
4.6 First Missing Positive
5. 暴力枚举
5.1 Subsets
5.1 Subsets II
5.3 Permutations
5.4 Letter Combinations of a Phone Number
6. 深度优先搜索
6.1 Palindrome Partitioning
6.2 Unique Paths
6.3 Unique Paths II
7. 回溯
8. 深搜与递归的区别
9. 分治法
10. 贪心法
10.1 Jump Game
10.2 Best Time to Buy and Sell Stock
10.3 Best Time to Buy and Sell Stock II
10.4 Longest Substring Without Repeating Characters
10.5 Container With Most Water
11. 动态规划
11.1 Triangle
11.2 Maximum Subarray
11.3 Palindrome Partitioning II
11.4 Maximal Rectangle
11.5 Best Time to Buy and Sell Stock III
11.6 Interleaving String
........持续更新中....
这些都是我分类节选的一些题,在这里推荐一个谷歌大佬的刷题笔记,每一道题的题解都写得非常清楚.
去年校招前,我也被刷题效率低下的问题所困扰,直到看完这本刷题笔记,按照笔记上分类的去刷,
每一个章节都先讲解框架思维,然后挑选非常典型的十几道LeetCode题进行实战讲解:

大家可以去下载下这本刷题笔记:
另外,我复习过程中还看了阿里大佬的笔记:
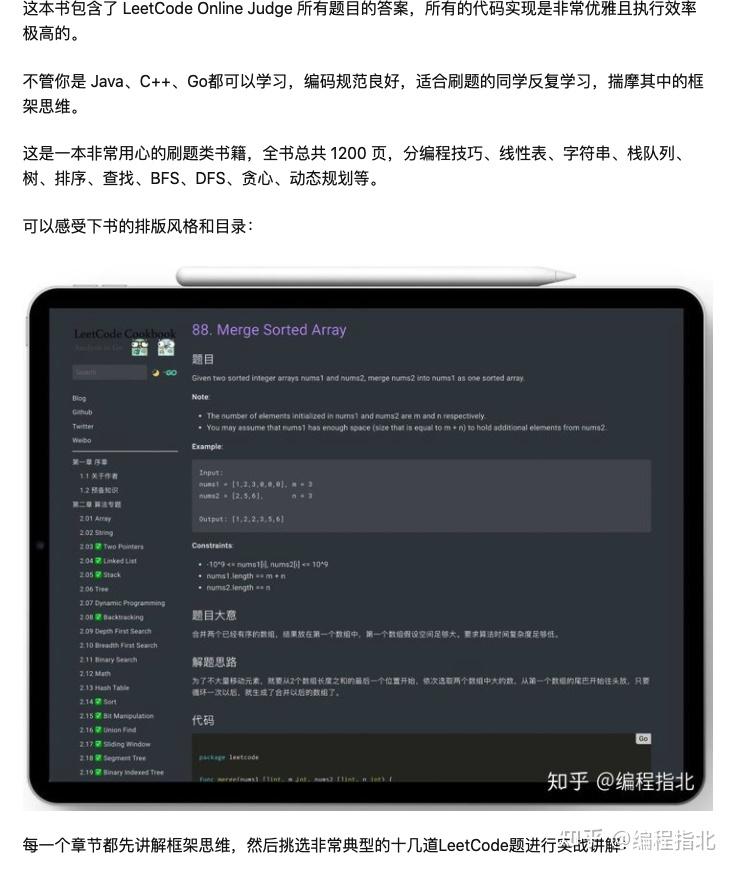
在这里一并分享给大家:
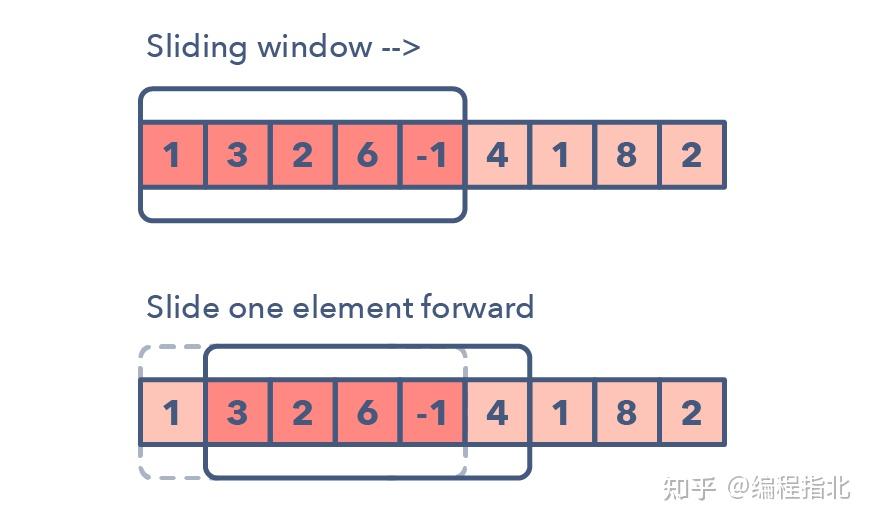
下面是一些你可以用来确定给定问题可能需要滑动窗口的方法:
问题的输入是一种线性数据结构,比如链表、数组或字符串你被要求查找最长/最短的子字符串、子数组或所需的值
你可以使用滑动窗口模式处理的常见问题:
大小为 K 的子数组的最大和(简单)带有 K 个不同字符的最长子字符串(中等)
寻找字符相同但排序不一样的字符串(困难)
2.二指针或迭代器
二指针(Two Pointers)是这样一种模式:两个指针以一前一后的模式在数据结构中迭代,直到一个或两个指针达到某种特定条件。二指针通常在排序数组或链表中搜索配对时很有用;比如当你必须将一个数组的每个元素与其它元素做比较时。
二指针是很有用的,因为如果只有一个指针,你必须继续在数组中循环回来才能找到答案。这种使用单个迭代器进行来回在时间和空间复杂度上都很低效——这个概念被称为「渐进分析(asymptotic analysis)」。尽管使用 1 个指针进行暴力搜索或简单普通的解决方案也有效果,但这会沿 O(n²) 线得到一些东西。在很多情况中,二指针有助于你寻找有更好空间或运行时间复杂度的解决方案。
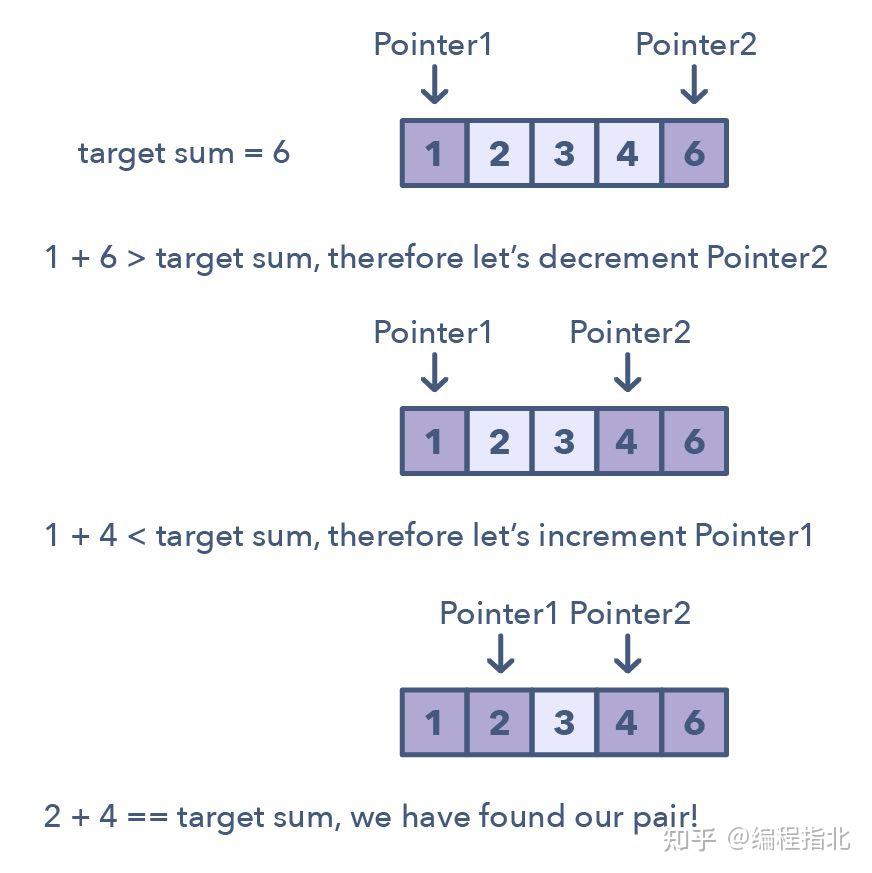
用于识别使用二指针的时机的方法:
可用于你要处理排序数组(或链接列表)并需要查找满足某些约束的一组元素的问题数组中的元素集是配对、三元组甚至子数组
下面是一些满足二指针模式的问题:
求一个排序数组的平方(简单)求总和为零的三元组(中等)
比较包含回退(backspace)的字符串(中等)
3.快速和慢速指针
快速和慢速指针方法也被称为 Hare & Tortoise 算法,该算法会使用两个在数组(或序列/链表)中以不同速度移动的指针。该方法在处理循环链表或数组时非常有用。
通过以不同的速度进行移动(比如在一个循环链表中),该算法证明这两个指针注定会相遇。只要这两个指针在同一个循环中,快速指针就会追赶上慢速指针。
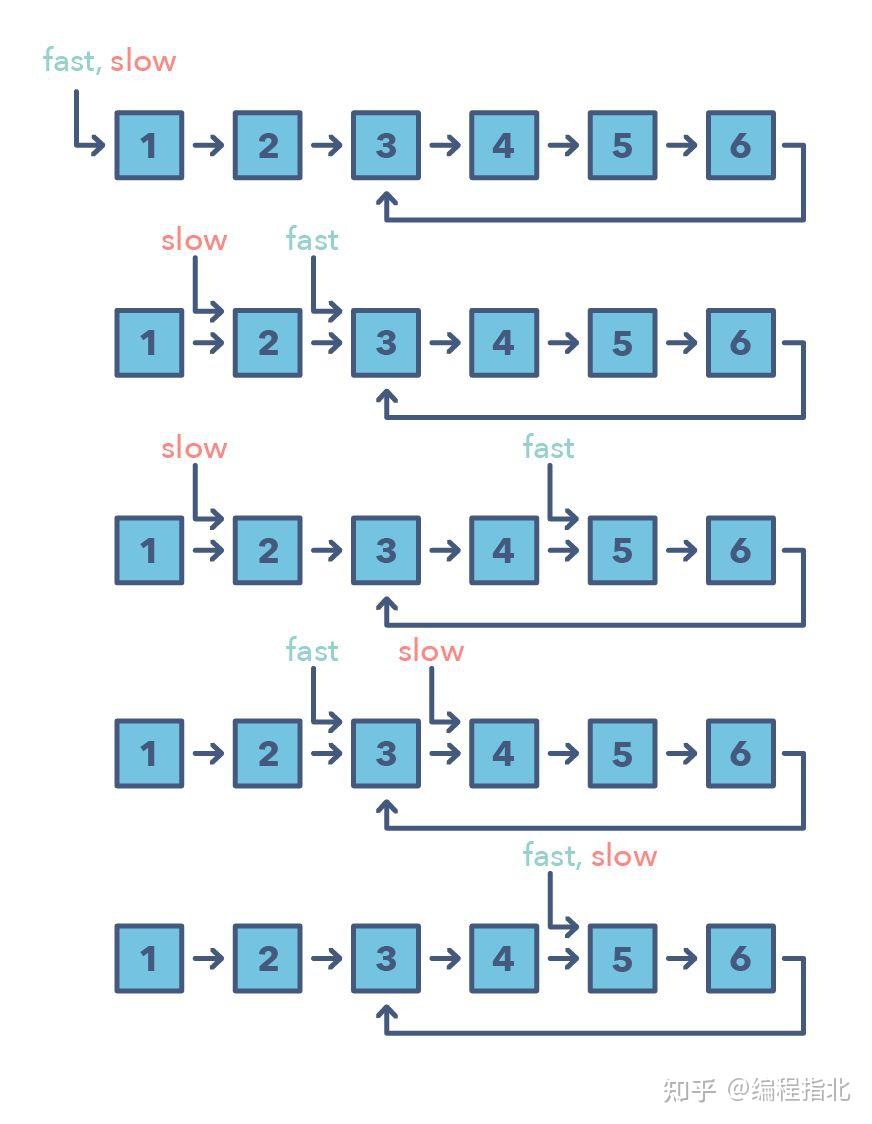
如何判别使用快速和慢速模式的时机?
处理链表或数组中的循环的问题当你需要知道特定元素的位置或链表的总长度时
何时应该优先选择这种方法,而不是上面提到的二指针方法?
有些情况不适合使用二指针方法,比如在不能反向移动的单链接链表中。使用快速和慢速模式的一个案例是当你想要确定一个链表是否为回文(palindrome)时。下面是一些满足快速和慢速指针模式的问题:
链表循环(简单)回文链表(中等)
环形数组中的循环(困难)
4.合并区间
合并区间模式是一种处理重叠区间的有效技术。在很多涉及区间的问题中,你既需要找到重叠的区间,也需要在这些区间重叠时合并它们。该模式的工作方式为:
给定两个区间(a 和 b),这两个区间有 6 种不同的互相关联的方式:
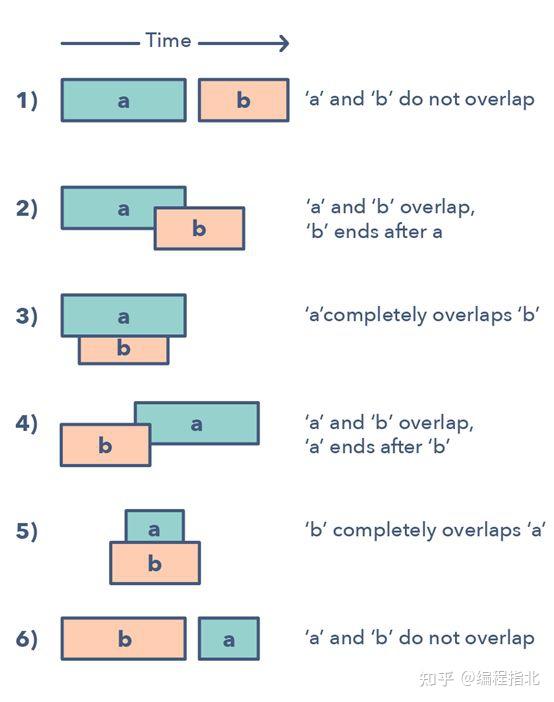
理解并识别这六种情况有助于你求解范围广泛的问题,从插入区间到优化区间合并等。
那么如何确定何时该使用合并区间模式呢?
如果你被要求得到一个仅含互斥区间的列表如果你听到了术语「重叠区间(overlapping intervals)」
合并区间模式的问题:
区间交叉(中等)最大 CPU 负载(困难)
5. 循环排序
这一模式描述了一种有趣的方法,处理的是涉及包含给定范围内数值的数组的问题。循环排序模式一次会在数组上迭代一个数值,如果所迭代的当前数值不在正确的索引处,就将其与其正确索引处的数值交换。你可以尝试替换其正确索引处的数值,但这会带来 O(n^2) 的复杂度,这不是最优的,因此要用循环排序模式。
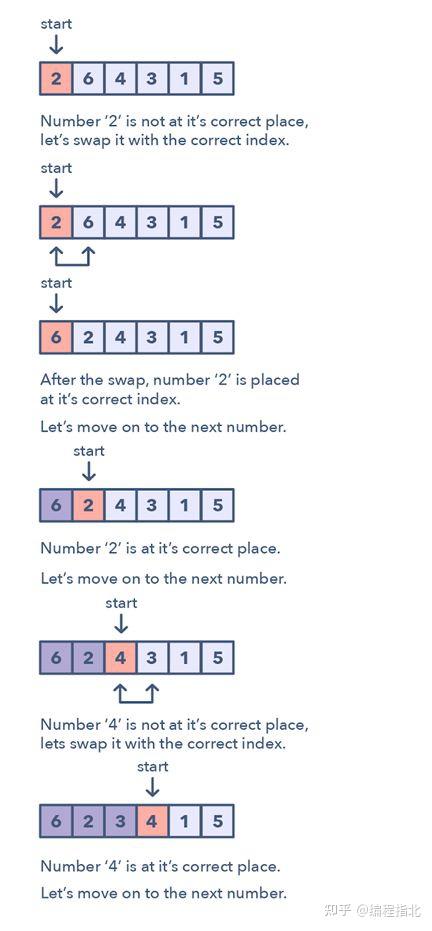
如何识别这种模式?
涉及数值在给定范围内的排序数组的问题如果问题要求你在一个排序/旋转的数组中找到缺失值/重复值/最小值
循环排序模式的问题:
找到缺失值(简单)找到最小的缺失的正数值(中等)
6.原地反转链表
在很多问题中,你可能会被要求反转一个链表中一组节点之间的链接。通常而言,你需要原地完成这一任务,即使用已有的节点对象且不占用额外的内存。这就是这个模式的用武之地。该模式会从一个指向链表头的变量(current)开始一次反转一个节点,然后一个变量(previous)将指向已经处理过的前一个节点。以锁步的方式,在移动到下一个节点之前将其指向前一个节点,可实现对当前节点的反转。另外,也将更新变量「previous」,使其总是指向已经处理过的前一个节点。
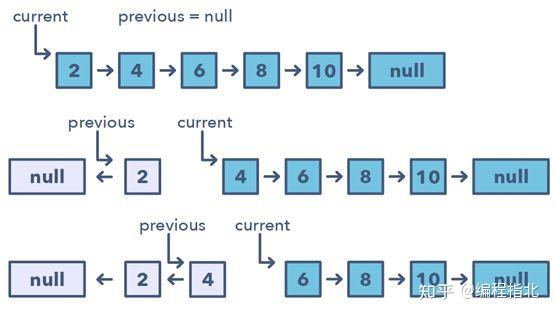
如何识别使用该模式的时机:
如果你被要求在不使用额外内存的前提下反转一个链表原地反转链表模式的问题:
反转一个子列表(中等)反转每个 K 个元素的子列表(中等)
7.树的宽度优先搜索(Tree BFS)
该模式基于宽度优先搜索(BFS)技术,可遍历一个树并使用一个队列来跟踪一个层级的所有节点,之后再跳转到下一个层级。任何涉及到以逐层级方式遍历树的问题都可以使用这种方法有效解决。
Tree BFS 模式的工作方式是:将根节点推至队列,然后连续迭代知道队列为空。在每次迭代中,我们移除队列头部的节点并「访问」该节点。在移除了队列中的每个节点之后,我们还将其所有子节点插入到队列中。
如何识别 Tree BFS 模式:
如果你被要求以逐层级方式遍历(或按层级顺序遍历)一个树Tree BFS 模式的问题:
二叉树层级顺序遍历(简单)之字型遍历(Zigzag Traversal)(中等)
8.树的深度优先搜索(Tree DFS)
Tree DFS 是基于深度优先搜索(DFS)技术来遍历树。
你可以使用递归(或该迭代方法的技术栈)来在遍历期间保持对所有之前的(父)节点的跟踪。
Tree DFS 模式的工作方式是从树的根部开始,如果这个节点不是一个叶节点,则需要做三件事:
1.决定现在是处理当前的节点(pre-order),或是在处理两个子节点之间(in-order),还是在处理两个子节点之后(post-order)
为当前节点的两个子节点执行两次递归调用以处理它们如何识别 Tree DFS 模式:
如果你被要求用 in-order、pre-order 或 post-order DFS 来遍历一个树如果问题需要搜索其中节点更接近叶节点的东西
Tree DFS 模式的问题:
路径数量之和(中等)一个和的所有路径(中等)
9. Two Heaps
在很多问题中,我们要将给定的一组元素分为两部分。为了求解这个问题,我们感兴趣的是了解一部分的最小元素以及另一部分的最大元素。这一模式是求解这类问题的一种有效方法。该模式要使用两个堆(heap):一个用于寻找最小元素的 Min Heap 和一个用于寻找最大元素的 Max Heap。该模式的工作方式是:先将前一半的数值存储到 Max Heap,这是由于你要寻找前一半中的最大数值。然后再将另一半存储到 Min Heap,因为你要寻找第二半的最小数值。在任何时候,当前数值列表的中间值都可以根据这两个 heap 的顶部元素计算得到。
识别 Two Heaps 模式的方法:
在优先级队列、调度等场景中有用如果问题说你需要找到一个集合的最小/最大/中间元素
有时候可用于具有二叉树数据结构的问题
Two Heaps 模式的问题:
查找一个数值流的中间值(中等)10. 子集
很多编程面试问题都涉及到处理给定元素集合的排列和组合。子集(Subsets)模式描述了一种用于有效处理所有这些问题的宽度优先搜索(BFS)方法。
该模式看起来是这样:
给定一个集合 [1, 5, 3]
1. 从一个空集开始:[[]]
2.向所有已有子集添加第一个数 (1),从而创造新的子集:[[], [1]]
3.向所有已有子集添加第二个数 (5):[[], [1], [5], [1,5]]
4.向所有已有子集添加第三个数 (3):[[], [1], [5], [1,5], [3], [1,3], [5,3], [1,5,3]]
下面是这种子集模式的一种视觉表示:
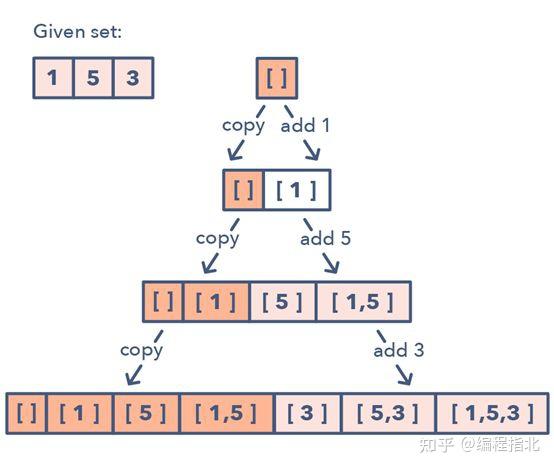
如何识别子集模式:
你需要找到给定集合的组合或排列的问题子集模式的问题:
带有重复项的子集(简单)通过改变大小写的字符串排列(中等)
11. 经过修改的二叉搜索
只要给定了排序数组、链表或矩阵,并要求寻找一个特定元素,你可以使用的最佳算法就是二叉搜索。这一模式描述了一种用于处理所有涉及二叉搜索的问题的有效方法。
对于一个升序的集合,该模式看起来是这样的:
1.首先,找到起点和终点的中间位置。寻找中间位置的一种简单方法是:middle = (start + end) / 2。但这很有可能造成整数溢出,所以推荐你这样表示中间位置:middle = start + (end — start) / 2。
2.如果键值(key)等于中间索引处的值,那么返回这个中间位置。
3.如果键值不等于中间索引处的值:
4.检查 key < arr[middle] 是否成立。如果成立,将搜索约简到 end = middle — 15.检查 key > arr[middle] 是否成立。如果成立,将搜索约简到 end = middle + 1
下面给出了这种经过修改的二叉搜索模式的视觉表示:
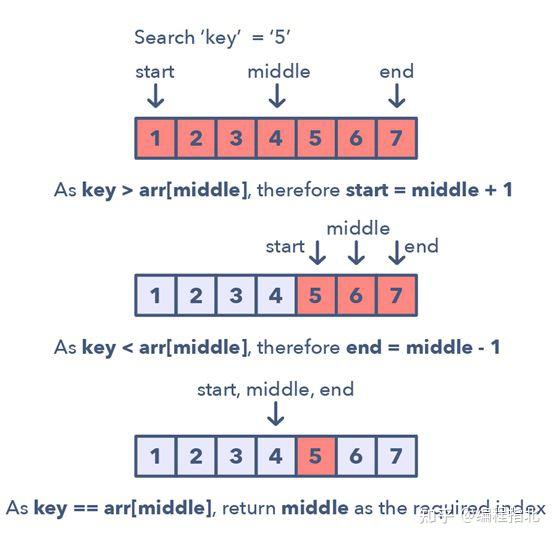
经过修改的二叉搜索模式的问题:
与顺序无关的二叉搜索(简单)在经过排序的无限数组中搜索(中等)
12. 前 K 个元素
任何要求我们找到一个给定集合中前面的/最小的/最常出现的 K 的元素的问题都在这一模式的范围内。
跟踪 K 个元素的最佳的数据结构是 Heap。这一模式会使用 Heap 来求解多个一次性处理一个给定元素集中 K 个元素的问题。该模式是这样工作的:
1. 根据问题的不同,将 K 个元素插入到 min-heap 或 max-heap 中
2.迭代处理剩余的数,如果你找到一个比 heap 中数更大的数,那么就移除那个数并插入这个更大的数
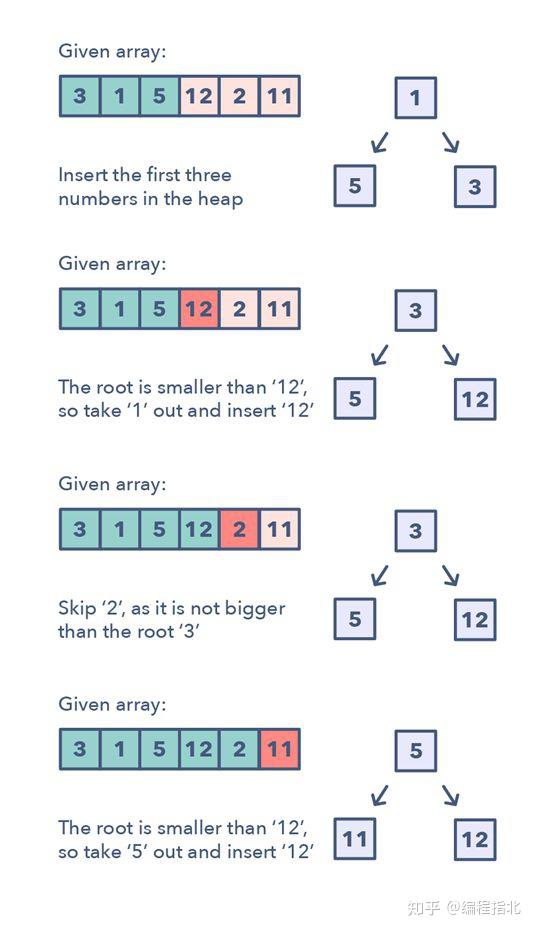
这里无需排序算法,因为 heap 将为你跟踪这些元素。
如何识别前 K 个元素模式:
如果你被要求寻找一个给定集合中前面的/最小的/最常出现的 K 的元素如果你被要求对一个数值进行排序以找到一个确定元素
前 K 个元素模式的问题:
前面的 K 个数(简单)最常出现的 K 个数(中等)
13. K 路合并
K 路合并能帮助你求解涉及一组经过排序的数组的问题。
当你被给出了 K 个经过排序的数组时,你可以使用 Heap 来有效地执行所有数组的所有元素的排序遍历。你可以将每个数组的最小元素推送至 Min Heap 以获得整体最小值。在获得了整体最小值后,将来自同一个数组的下一个元素推送至 heap。然后,重复这一过程以得到所有元素的排序遍历结果。
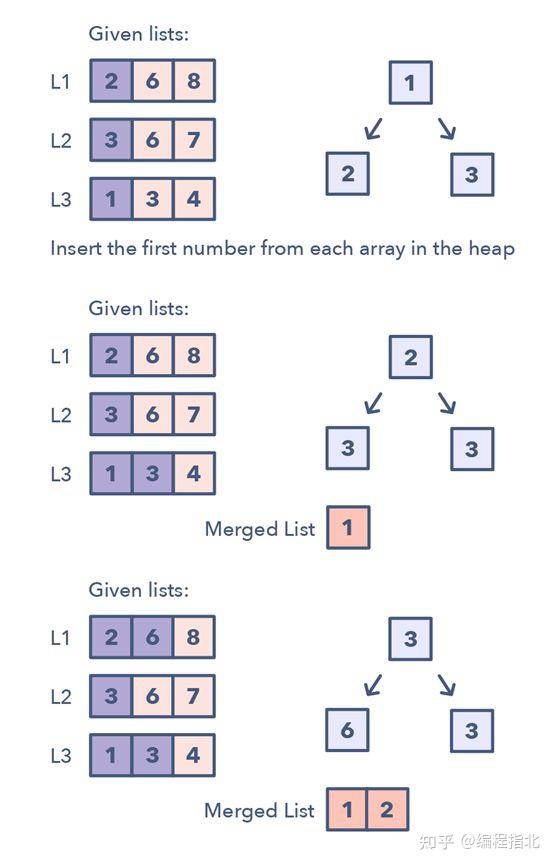
该模式看起来像这样:
1.将每个数组的第一个元素插入 Min Heap
2.之后,从该 Heap 取出最小(顶部的)元素,将其加入到合并的列表。
3.在从 Heap 移除了最小的元素之后,将同一列表的下一个元素插入该 Heap
4.重复步骤 2 和 3,以排序的顺序填充合并的列表
如何识别 K 路合并模式:
具有排序数组、列表或矩阵的问题如果问题要求你合并排序的列表,找到一个排序列表中的最小元素
K 路合并模式的问题:
合并 K 个排序的列表(中等)找到和最大的 K 个配对(困难)
14. 拓扑排序
拓扑排序可用于寻找互相依赖的元素的线性顺序。比如,如果事件 B 依赖于事件 A,那么 A 在拓扑排序时位于 B 之前。
这个模式定义了一种简单方法来理解执行一组元素的拓扑排序的技术。
该模式看起来是这样的:
1.初始化。a)使用 HashMap 将图(graph)存储到邻接的列表中;b)为了查找所有源,使用 HashMap 记录 in-degree 的数量
2.构建图并找到所有顶点的 in-degree。a)根据输入构建图并填充 in-degree HashMap
3.寻找所有的源。a)所有 in-degree 为 0 的顶点都是源,并会被存入一个队列
4.排序。a)对于每个源,执行以下操作:i)将其加入到排序的列表;ii)根据图获取其所有子节点;iii)将每个子节点的 in-degree 减少 1;iv)如果一个子节点的 in-degree 变为 0,将其加入到源队列。b)重复 (a),直到源队列为空。

如何识别拓扑排序模式:
处理无向有环图的问题如果你被要求以排序顺序更新所有对象
如果你有一类遵循特定顺序的对象
拓扑排序模式的问题:
任务调度(中等)一个树的最小高度
总结:大家一定要先熟悉基本的数据结构与算法,然后再把这篇文章中列举的常见题目刷一遍,刷的时候注意看评论区一些优秀的解法,一举反三,尤其要重视动态规划,一般动态规划相关的题连续做个三十多道也就差不多了,我都列在了回答中,大家记得收藏,点赞,免得下次找不到啦~
整理不易,觉得不错的话,记得帮我 @编程指北 点个赞哟~
上一篇:少儿编程学什么
下一篇:学习计算机科学的顺序是什么?
知识阅读





软件推荐
更多 >-
 查看
查看皓盘云建最新版下载v9.0 安卓版
53.38MB |商务办公
-
 查看
查看ris云客移动销售系统最新版下载v1.1.25 安卓手机版
42.71M |商务办公
-
 查看
查看粤语翻译帮app下载v1.1.1 安卓版
60.01MB |生活服务
-
 查看
查看人生笔记app官方版下载v1.19.4 安卓版
125.88MB |系统工具
-
 查看
查看萝卜笔记app下载v1.1.6 安卓版
46.29MB |生活服务
-
 查看
查看贯联商户端app下载v6.1.8 安卓版
12.54MB |商务办公
-
 查看
查看jotmo笔记app下载v2.30.0 安卓版
50.06MB |系统工具
-
 查看
查看鑫钜出行共享汽车app下载v1.5.2
44.7M |生活服务
精选栏目
热门推荐


-
1
 联想笔记本电脑清理灰尘详细步骤
联想笔记本电脑清理灰尘详细步骤2022-03-26
-
2
 神舟bios设置图解教程
神舟bios设置图解教程2022-03-26
-
3
 联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议
联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议2022-03-26
-
4
 联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程
联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程2022-03-26
-
5
 ACPI是什么?BIOS中怎么设置ACPI?
ACPI是什么?BIOS中怎么设置ACPI?2022-03-26
-
6
 联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)
联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)2022-03-26
-
7
 鸿蒙系统能安装vscode吗
鸿蒙系统能安装vscode吗2022-03-26
-
8
 fast路由器设置网址192.168.1.1,falogin.cn密码
fast路由器设置网址192.168.1.1,falogin.cn密码2022-02-15
-
9
 192.168.1.62登录入口管理网址
192.168.1.62登录入口管理网址2022-03-26
-
10
 联想笔记本装系统怎么进入PE图文教程
联想笔记本装系统怎么进入PE图文教程2022-02-14





-
1

-
2
机器人战斗竞技场手机版下载v3.71 安卓版
其它手游 -
3
果冻人大乱斗最新版下载v1.1.0 安卓版
其它手游 -
4
王者100刀最新版下载v1.2 安卓版
其它手游 -
5
trueskate真实滑板正版下载v1.5.102 安卓版
其它手游 -
6
矢量跑酷2最新版下载v1.2.1 安卓版
其它手游 -
7
休闲解压合集下载v1.0.0 安卓版
其它手游 -
8
指尖游戏大师最新版下载v4.0.0 安卓版
其它手游 -
9
飞天萌猫下载v3.0.3 安卓版
其它手游 -
10
火柴人越狱大逃脱下载v1.1 安卓版
其它手游