游戏编程精粹1学习笔记第一章·通用编程技术(3)
发表时间:2022-03-25来源:网络
九、快速数据载入技巧
如何变得更快是游戏编程中永恒的挑战。但随着游戏关卡变得越来越大,你所需的载入时间也变得越来越长。本节的技巧可以减少游戏关卡载入时间。
1.预处理你的数据
在所有你能做的事情里面,最重要的是尽可能去预处理关卡数据。这可以通过使用独立的工具程序,如用来编辑游戏数据的独立关卡编辑器,或者在游戏中开发中自定的数据,打包代码。
为了最终获得更短的数据载入时间,需要将你的数据预处理为游戏中最终使用的格式。只需要做些计划,就可以让你的C++类或C结构的布局更适合高速载入。所有需要被存储的数据都必须是非静态成员变量,并且不能将指针保存到数据文件中。
如果你的数据里面需要用到指针,则必须确保在它们被完全载入并正确设置以后才使用,因为指针在载入后通常都指向无效数据。另外一种解决方法是将指针改为句柄或索引。
因为C++使用虚函数表,所以必须确保不在类里面使用任何虚函数,否则在用无效数据覆盖虚函数表后,虚函数会调用内存中任意位置的代码。如果你想真正安全,可以尝试将所有的访问函数变为静态,以保证它们不会被包含在你的数据里。
2.保存你的数据
无论是游戏中还是在独立的预处理工具中,一旦数据被填充到结构中,就可以将它们写到硬盘上。对C++来说,可以使用this指针和sizeof()来处理类。对C来说,只需要结构指针和sizeof()来处理结构。
下面的例子代码演示如何在C++中对有成员函数的数据类进行载入和保存。
#include class GameData { public: bool Save(char *fileName); bool Load(char *fileName); bool BufferedLoad(char *fileName); private: //一次只打开一个文件 static File *fileDescriptor; //游戏数据 int data[1000]; //使用你自己的数据格式替换这个字段 }; bool GameData::Save(char *fileName) { fileDescriber = fOpen(fileName, "wb"); if(fileDescriber) { fwrite(this, sizeof(GameData), 1, fileDescriptor); fclose(fileDescriptor); //报告写文件成功 return TRUE; } else { //报告写文件出错 return FALSE; } }3.使用简单方法载入你的数据
使用上述方法保存数据,可使应用程序在以后需要载入关卡时,非常轻松地读回它们。只需要将数据读回到游戏中和写入它们时相同的结构或类中。
bool GameData::Load(char *fileName) { //以读模式打开文件 fileDescriptor = fopen(fileName, "rb"); if(fileDescriptor) { fread(this, sizeof(GameData), 1, fileDescriptor); fclose(fileDescriptor); //报告读取文件成功 return TRUE; } else { //报告读取文件错误 return FALSE; } }4.更安全地载入你的数据
对于某些游戏控制台硬件,至少有一件非常重要的事情需要注意。一些系统总是要读完当前磁盘扇区。例如,Sony PS从CD-ROM读取的数据一定是2048字节的倍数。也就是说,如果要直接读取数据到你的结构中,而且结构的长度不是2048字节的倍数,那你就破坏了紧接在那个结构之后的内存数据。我们称之为“memory stomp”。
为避免这种memory stomp,需要有一个足够大的临时缓冲区来保存填充到2K边界的数据文件。如果你需要读多个文件,不要每次都分配和释放一个新的缓冲区。而是改用一个最大缓冲区,只分配一次,并且在所有的读取操作中重用它。在完成所有的读取操作后再释放它。
如果你使用的系统只有很少量的内存,也许所有的内存都已有安排,同时动态内存也被一起禁止。在这种情况下,需要事先在内存中某处确定一个缓冲区,这样在你需要读取文件时它不会被使用。使用它作为临时缓冲区而避免使用动态内存分配,如下:
//检查你的硬件中一次读取块的大小 //将值放在这个定义中 #define READ_GRANULARITY 2048 bool GameData::BufferedLoad(char *fileName) { //确认读缓冲区有足够空间 //如果使用READ_GRANULARITY的倍数,使用的空间会小一些,但下面的方法会更快一点 char *tempBuffer = new char[sizeof(GameData) + READ_GRANULARITY]; if(!tempBuffer) { //不能分配缓冲区,返回错误代码 return FALSE; } fileDescriptor = fopen(fileName, "rb"); if(fileDescriptor) { fread(tempBuffer, sizeof(GameData), 1, fileDescriptor); fclose(fileDescriptor); memcpy(this, tempBuffer, sizeof(GameData)); delete tempBuffer; //报告读文件成功 return TRUE; }else { delete tempBuffer; //报告读文件错误 return FALSE; } }现在已经掌握了高度优化的关卡载入。通过预处理数据,你将节省下降数据转换为可用格式的CPU时间,并且减少了需要读取数据的总量。既快又小才是最好的优化。
十、基于帧的内存分配
1.常规内存分配的挑战
包括malloc()和new在内的标准内存分配系统的最大问题在于,内存会变成碎片,从而导致游戏性能下降,并且可能导致无法分配一个可用的大内存块。但在一个应用程序请求分配一块内存时,成熟的操作系统,如UNIX和Microsoft Windows,会使用高级内存管理系统将物理内存块在逻辑上组合到一起,以提供请求的连续内存块。但是这个组合需要消耗很多本用于游戏等CPU指令周期。而对于只有很小的库函数集的家用游戏机来说,并没有成熟的内存管理器可用。
2.介绍基于帧的内存
解决这些传统内存分配难题的一种办法是,采用基于帧的内存。基于帧的内存可以消除内存碎片的问题并且使用起来非常快速。但是它不能用来作为类似malloc()和new的基于一般目的的内存分配系统。基于帧的内存最适合用于游戏和关卡初始化模块。
基于帧的内存以类似堆栈的方式工作。在初始化时,游戏从操作系统分配一个单独的内存块,并交由帧内存系统使用和管理。这个内存块在游戏的整个生命周期中只分配一次,直至游戏结束才被操作系统收回。下面的代码将完成初始化帧内存系统的工作。
typedef unsigned char u8; typedef unsigned int uint; #define ALIGNUP(nAddress, nBytes) ( ( (uint)nAddress ) + (nBytes-1) & (~(nBytes-1)) ) static int _nByteAlignmant; //内存对齐的字节数 static u8 *_pMemoryBlock; //malloc()返回值 static u8 *_apBaseAndCap[2]; //[0]=基指针,[1]=顶指针 static u8 *_apFrame[2]; //[0]=低帧指针, [1]=高帧指针 //必须在游戏初始化时调用一次且最多一次 //nByteAlignment必须是2的幂 //成功时返回0,错误发生是返回1 int InitFrameMemorySystem(int nSizeInBytes, int nByteAlignment){ //必须保证nSizeInBytes是nByteAlignment的整数倍 nSizeInBytes = ALIGNUP(nSizeInBytes, nByteAlignment); //首先分配我们的内存块 pMemoryBlock = (u8 *)malloc( nSizeInBytes + nByteAlignment ); if( _pMemoryBlock == 0 ){ //没有足够内存,返回错误标志 return 1; } _nByteAlignment = nByteAlignment; //设置基指针 _apBaseAndCap[0] = (u8 *)ALIGNUP( _pMemoryBlock, nByteAlignment ); //设置顶指针 _apBaseAndCap[1] = (u8 *)ALIGNUP( _pMemoryBlock + nSizeInBytes, nByteAlignment ); //最后,初始化低帧指针和高帧指针 _apFrame[0] = _apBaseAndCap[0]; _apFrame[1] = _apBaseAndCap[1]' return 0; }停止帧内存系统:
void ShutdownFrameMemorySystem(void){ free(_pMemoryBlock); }函数InitFrameMemorySystem()在游戏初始化时被调用一次且最多一次,传入参数包括帧内存系统管理的最大内存数和字节对齐数。所有通过帧内存系统进行的分配操作都必须保证内存对齐。注意,ALIGNUP()宏需要nBytes参数值为2的幂。
3.分配和释放内存
分配帧内存的工作类似堆栈操作。一个系统调用从一个或两个堆中请求一块内存。如果制定了低堆,低堆帧指针将根据分配空间大小而增长,改变前的值被返回。低堆帧指针总是指向下一个可分配的内存字节。另一方面,如果指定了高堆,高堆帧指针将根据分配空间大小而减小,改变后的新值被返回。这是因为高堆帧指针总是指向最后分配的内存字节。如果两个帧指针彼此交错,则没有足够内存满足需求。下面的函数将完成分配操作:
//返回内存块的基指针,或者在没有足够内存时返回0 //nHeapNum是堆编号:0=低,1=高 void *AllocFrameMemory( int nBytes, int nHeapNum ){ u8 *pMem; //首先,将请求大小内存对齐: nBytes = ALIGNUP( nBytes, _nByteAlignment ); //检查可用内存: if( _apFrame[0]+nBytes > _apFrame[1]){ //没有足够内存 return 0; } //现在完成内存分配操作: if(nHeapNum){ //从高堆向下分配 _apFrame[1] -= nBytes; pMem = _apFrame[1]; }else{ //从低堆向上分配 pMem = _apFrame[0]; _apFrame[0] += nBytes; } return (void *)pMem; }这个函数能非常快速地完成基于帧的内存分配。既然帧内存通过类似堆栈的方式分配,它也需要使用同样的方式释放。这就是帧被引入的原因。帧是游戏从内存系统获取用来释放内存的句柄。内存只能通过帧来释放。帧起到类似系统分配的内存页中书签的作用。当一个帧被释放后,在此帧被获取后分配的索引内存都将被释放。下面的函数表示从高堆或低堆获取一个帧。
typedef struct{ u8 *pFrame; int nHeapNum; }Frame_t; //返回一个可以在以后用于释放内存的帧句柄 //nHeapNum是堆的编号:0=低,1=高 Frame_t GetFrame(int nHeapNum){ Frame_t Frame; Frame.pFrame = _apFrame[nHeapNum]; Frame.nHeapNum = nHeapNum; return Frame; }对内存系统来说,一个帧只是一个堆编号和当前堆的帧指针的拷贝。但对于游戏,它只是一个简单的句柄,Frame_t。要释放内存,我们实现了下面的函数:
void ReleaseFrame(Frame_t Frame){ _apFrame[Frame.nHeapNum] = Frame.pFrame; }游戏调用ReleaseFrame()函数来释放从调用GetFrame()函数获取帧以来分配的所有内存。倘若释放帧的顺序或获取帧的顺序相反,那么游戏同时可以分配多少个帧并没有限制。无论如何,内存系统并不要求帧被释放。举例来说,如果获取了帧1、帧2和帧3,释放帧3后直接释放帧1,并且永远不释放帧2是有效的操作。
4.例子
考虑下面的应用程序实例:
#define _HEAPNUM 1 //这里我们将使用高堆(1) extern int GetObjectSize( const char *pszObjectName ); extern int LoadFromDisk( const char *pszObjectName, void *pLoadAddress); //我们的CopCar将被读到这里 static void *_pObject1; //RobberCar将被读到这里 static void *_pObject2; //把CopCar和RobberCar对象从磁盘读到_HEAPNUM中 //如果成功传回0,否则传回1 int LoadCarObjects(void){ Frame_t Frame; //得到一个帧柄 Frame = GetFrame( _HEAPNUM ); //尝试读取CopCar对象 _pObject1 = LoadMyObject("CopCar"); if(_pObject1 == 0){ //不能读取对象。释放内存 ReleaseFrame(Frame);r return 1; } //尝试读取RobberCar对象 _pObject2 = LoadMyObject("RobberCar"); if(_pObject2 == 0){ //不能读取对象,释放内存 ReleaseFrame(Frame); return 1; } return 0; } //从_HEAPNUM分配内存,同时把指定的对象从磁盘读到已分配的内存中 //如果成功,传回对象指针,否则传回0 void *LoadMyObject( const char *pszObjectName ){ int nObjectSize; void *pObject; nObjectSize = GetObjectSize( pszObjectName ); if( nObjectSize == 0 ){ //不能准确得到对象大小 return 0; } pObject = AllocFrameMemory( nObjectSize, _HEAPNUM ); if( pObject == 0 ){ //内存不足 return 0; } if( LoadFromDisk( pszObjectName, pObject )){ //不能从磁盘上读取对象 return 0; } return pObject; }在前面的例子中,函数LoadCarObjects()获取了一个帧,但只在载入对象出现问题时释放它。如果两个对象都被正常载入,帧不会被释放并且函数返回正常的内存。高级函数可以获取它自己的帧以封装包括LoadCarObjects()以内的所有对象载入函数。当需要释放所有对象存在时,高层函数只需要简单地使用其获取的帧调用ReleaseFrames()函数,即可完成所有内存释放操作。
5.结论
既然基于帧的内存以类似堆栈的方式工作,它就需要帧被以与获取顺序相反的顺序释放;苟泽内存可能被破坏。检测释放违反这个条件的方法很简单。可以使用以下函数释放帧的函数:
void ReleaseFrame( Frame_t Frame ){ //检测低堆中释放操作的有效性 assert( Frame.nHeapNum==1 || (uint)Frame.pFrame=(uint)_apFrame[1]); //释放帧 _apFrame[Frame.nHeapNum] = Frame.pFrame; }这段代码可以在游戏的调试版本中检测出以不正确的顺序释放帧的企图。还可以加入更多的断言以检测其他参数的有效性问题。
最后需要说的是,对于使用多种无关的内存类型(主存、声音、贴图、图形等)的游戏平台,对于每一种内存类型,我们可以很容易地用一个基于帧的内存系统来实现,然后使用主帧将他们联系到一起。回想一下前面的例子。假设LoadFromDisk()为特定模型载入图形、贴图和声音,图形被放在系统内存,贴图放入贴图内存,而声音放入声音内存。在这种情况下,需要有三个独立帧内存系统通过主帧联系到一起:
typedef struct{ Frame_t SysmemFrame; //系统内存帧 Frame_t TexmemFrame; //贴图内存帧 Frame_t SoundmemFrame; //声音内存帧 }MasterFrame_t;十一、简单快速的位数组
我们喜欢位操作,因为它们速度快,且能够高效地组织数据;但我们也讨厌位操作,因为它们容易出错且跟机器字长相关。我们真正需要的是一种抽象的位操作,能够带给我们位操作的优点,但隐藏繁琐的底层细节。
1.概述
本文通过三个C++类实现位数组。基类BitArray是一个简单的一维位数组。它的子类BitArray2D是一个二维位数组,而TwoBitArray是一个值为0~3的整数的数组。所有的类都可以通过类似英语的语法或者通过常用的操作符进行维护。这些类具有清除的语法、可移植性、范围检测,正确地使用了const并具有很高的性能。
C++标准模板库(STL)在位集头文件中包含一个一维位数组。尽管具有丰富的特性,但大多数实现被隐藏,并且难以扩充或修改。一些STL实现也依赖于部分没有被某些编译器实现的C++标准,如成员模板和名字空间。
2.位数组
基类BitArray使用起来跟普通C++中的bool类型数组很相似,但当然你也可以将位看作值为0或1的整数。这些位存储在字节序无关的long类型缓冲区中。语法上你可以将BitArray以与标准C++数组相同的方式使用,但它还同时具有动态数组的优点和附加的操作符。例如,你可以像如下代码一样操作:
BitArray bits(num_bits), other_bits(num_bits); bits.Clear(); bits[10] = true; if((bits & other_bits).AllBitsFalse()) {}该类实现了标准位操作运算符 &、|、^、&=、|=、^=和~。但没有实现移位运算符。
为保障高性能,BitArray在创建时不做任何初始化工作。Clear()方法设置所有位为false。作为优化特性之一,小的BitArray可以存储在一个机器字中而无需分配额外的内存。使得这个类同样适用于很小的标志集合。语法:
flags[FLAG_INDEX] = true;比传统的语法更加清晰
flags |= 1 x*src->x) + (src->y*src->y) + (src->z*src->z) ); assert(length != 0 ); //检查长度不能为零 dst->x = src->x / length; dst->y = src->y / length; dst->z = src->z / length; }因为VectorNormalize函数需要尽可能地块,我们不能在发布版本中浪费时间去检测假设是否成立。可是当游戏在开发期间,我们又需要知道所有可能发生的问题。这就是断言能够大有作为的地方了。assert宏不会被编译到最终发布版本中,因此假设可以在开发期间被测试并在编译发布版本时自动被删除。这种机制允许你在代码中大范围使用断言,而无需担心在游戏发布前需要将其删除。
既然assert宏不会被编译到发布版本中,所以在断言中不会修改你的程序状态就至关重要。作为一个法则,不要在断言中调用函数或修改任何变量;否则你的调试和发行版本将由不同的行为,导致难以预料的严重问题。
2.Assert技巧 #1:嵌入更多信息
传统assert宏的一个缺点是无法告诉你较多信息。如果assert(src != 0)失败了,它只会在断言对话框中体式字符串“src != 0”。不幸的是,这不能给你足够信息来处理问题。有一项技术是,嵌入更多信息到你的条件中。
void VectorNormalize( Vec* src, Vec* dst ) { float length; assert( src != 0 && "VectorNormalize: src vector pointer is NULL" ); assert( dst != 0 && "VectorNormalize: dst vector pointer is NULL" ); length = sqrt( (src->x*src->x) + (src->y*src->y) + (src->z*src->z) ); assert(length != 0 && "VectorNormalize: src vector is zero length" ); dst->x = src->x / length; dst->y = src->y / length; dst->z = src->z / length; }当这段代码中第一个断言失败时,断言对话框将显示字符串“src != 0 && "VectorNormalize: src vector pointer is NULL"”。即使是你的测试者正在运行游戏,它们也可以告诉你断言失败的函数名,以及相关原因。
3.Assert技巧 #2:嵌入更多更多信息
有时程序员会在程序运行到一个无法预料的位置时简单地输入assert(0)。你可以使用相同的技巧,通过简单的取反字符串导致失败来插入描述字符串。例如:
assert( !"VectorNormalize: The code should never get here" );4.Assert技巧 #3:使之更好用一些
前面两个技巧可以通过写一个简单的宏合并到一起。这个宏接受两个参数,第一个参数是需要计算的条件;第二个则是描述字符串。它模拟了前两个技巧,但便于输入和阅读:
#define Assert(a,b) assert( a && b )下面两行使用了新的宏:
assert( src != 0 , VectorNormalize: src vector pointer is NULL"); assert( 0, "VectorNormalize: The code should never get here" );5.Assert技巧 #4:编写自己的assert宏
最终,所有人都会使用被真正定制后的assert宏。通过编写自己的断言对话框代码可以获得更多的控制并可新增特性。
标准C的断言有一个有一个非常让人讨厌的问题:它会在调试器里中断代码到assert.c文件,而不是你程序中断言出现的行。通过编写自己的assert宏,调试器可以直接中断到输入断言的行。这就避免了为找到你实际感兴趣的代码而所做的毫无意义的堆栈跟踪。下面是一个自定义assert宏的例子:
#if defined(_DEBUG) extern bool CustomAssertFunction(bool, char*, int, char*); #define Assert(exp, description) if(CustomAssertFunction((int)(exp), description, _LINE_, _FILE_)) { _asm { int 3 } } #else #define Assert( exp, description ) #endif上面的宏调用CustomAssertFunction函数(需要由你自己编写)。CustomAssertFunction函数应该弹出一个显示断言信息的对话框,允许使用者继续或中断程序运行。如果使用者选择中断,CustomAssertFunction函数应该返回TRUE,调试器则中断到断言所在行(这就是int3指令在PC上所做的)。否则,函数应该返回FALSE,程序将继续运行。
6.Assert技巧 #5:无价之宝
一旦有一个自定义的assert宏,你就可以为你的断言对话框增加一个“总是忽略”选项。这是一个令人惊异的特性,它允许你在忽略一个断言后从此再不提示此断言。这在某个断言对每一帧都会失败的情况下特别有用,它使得你能够在继续运行程序时避免上百万次地点击断言对话框。要实现这个特性,每个断言都必须跟踪自己是否被忽略的状态,并禁止自己在此后被激发。
实现“总是忽略”的方法是在assert宏中使用一个静态布尔变量。这个布尔变量保存此断言是否被忽略。初始此布尔值设置为FALSE。当代码执行,它在计算断言条件前检测这个布尔值,如果布尔值为FALSE,则将执行此布尔值的指针作为参数来调用CustomAssertFunction函数。如果断言条件失败并且使用者在断言对话框中选择“总是忽略”,它就设置此布尔值为TRUE。下列代码实现了这个宏:
#if defined(_DEBUG) extern bool CustomAssertFunction(bool, char*, int, char*); #define Assert(exp, description) { static bool ignoreAlways = false; if( !ignoreAlways ){ if(CustomAssertFunction((int)(exp), description, _LINE_, _FILE_)) { _asm { int 3 } } } } #else #define Assert( exp, description ) #endif7.Assert技巧 #6:给“超级铁杆”
关于在VectorNormalize函数中清晰显示的断言,有一个啰嗦的问题。问题在于,错误的来源并不在VectorNormalize函数内。真正的错误只会在调用VectorNormalize函数的函数中发生,这将范围缩小到只剩几百个过程!如果断言失败时没有运行调试器,断言实际上并没有起任何作用。令人惊讶的是,这种情况非常普遍,因为测试者几乎都不会通过调试器来运行游戏。
一个简单的解决方法是在断言对话框中提供堆栈信息!
8.Assert技巧 #7:让它更简单——复制和粘贴
如果一个简单的技巧就能简化大量要做的工作,那实在是太酷了!本技巧就可以。如果断言提供了大量重要调试信息,为什么不直接让它简单易懂,以使测试者技能正确转告呢?
在Windows环境,你可以在断言对话框中提供一个按钮将信息复制到剪贴板的工作。只需要轻松地点击几下鼠标,任何人都能轻松复制和粘贴assert到电子邮件或错误报告中。这个简单而功能强大的办法能帮助你的测试者将精确、有意义的信息传达给程序员。
下面的代码可以复制任意字符串到剪贴板中。
if( OpenClipboard(NULL) ) { HGLOBAL hMem; char szAssert[256]; char *pMem; sprintf(szAssert, "Put assert info here" ); hMem = GlobalAlloc( GHND|GMEM_DDESHARE, strlen( szAssert)+1 ); if( hMem ){ pMem = (char*)GlobalLock( hMem ); strcpy( pMem, szAssert ); GlobalUnlock( hMem ); EmptyClipboard(); SetClipboardData( CF_TEXT, hMem ); } CloseClipboard(); }十四、Stats:实时统计和游戏内调试
每个人实际调试的时间都超过了自己当初的预期时间。通过开发一个实时调试和数据编辑系统可以缩减大量时间。这个系统可以使开发人员通过在运行于目标平台的实时系统中更简单地进行调试和数据追踪来提升工作效率。这一技术已经被应用于面向PC和游戏机的商业产品。系统的名字是从统计延伸来的,因为这个想法的最初目的是在游戏中单独显示供调试使用的数字统计信息。
文中描述的工具集非常易于实现,具有很强的可扩展性,并可针对游戏软件的设计和测试阶段的多个方面,具有很强实用性。也就是说你可以很容易地为你的需求定制此系统,并能够在以后的项目中适应变化且沿用下去。
1.Why:需求驱动的技术
PC和游戏机系统在调试全屏实时程序时都存在很多问题。在PC上,你必须借助基于网络的远程调试、多屏幕系统,或者在调试会话期间在窗口模式和全屏模式之间切换。有些时候调试环境在系统运行时不允许访问部分或所有数据,并且在实时循环中错误的断点还可能导致系统锁死。
每位在实时环境下工作的程序员肯定都碰到过使用普通调试方法几乎永远无法发现的bug。有时代码在你单步跟踪时运行结果不同。有时你需要调试一个实时网络游戏来重新一个问题;或者更麻烦,需要同时调试一个网络游戏的两端。
从某种角度来说,基本上每个项目都需要一个帧率计数器在屏幕上显示一些实时系统的数据。其他的一些常用项目,如多边形数、选择效率、基于视角内容的一般执行时间等,难以从调试器中获取,但易于在实时系统中追踪,这使得需要构造一个能够显示任意数字列表的系统。
2.How:一个进化过程
对很多项目来说,通过可编辑版本的Stats比编写特殊调试代码更简单。Stata可以用来开关局部特写,并且可以将一组相关特性显示在一页中。通过这些设置,你仍可以在系统处于运行时,获取一些关于系统行为的详细数据。
3.What:一个基于C++类的系统
使用Stat积累和继承类型为每个显示数据类型,完成类似Stats系统的实现只需要不到一周时间来进行设计。系统包括一个基本的作为所有东西的容器的Stat类,和一些包括多项需要显示内容的单独页。
使用什么方式将Stats显示到屏幕上需要进行权衡。如果在Stat类的子类中放入自己的打印代码将减少可移植性,但可以做到任何你想做的事情,如用柱状图显示统计信息。如果简单的将统计信息作为字符串输出到显示设备,实现将具有很好的可移植性并易于在跨平台开发中使用。
4.Where:可用性
一个Stats系统的显著应用是用户界面原型,在还没有真实屏幕可用之前可在此设置屏幕流程。一个典型的菜单可以在几分钟内设置好,并允许绕过还没有完成的用户界面代码。只
需简单地编写临时Stats系统,就不必等待其他人完成核心代码快才能继续工作。
可以将Stats系统合并到游戏中地目录和路径编辑中去。Stats可以在游戏运行中用于设置载入、移动和保存指令。它也可以被用来编辑AI属性并载入和保存任意类型地数据文件,包括在内存dump类中地批处理脚本文件。也可以被用来出书构造基于世界位置地帧计算时间统计图表来显示高负载区域。
Stats系统也可以给出方便地方法来跳到任意游戏级别。在游戏中任何你希望重设、打开或关闭地任意多选项都可以用Stats系统来处理。例如一些高亮冲突、调整摄像机行为等等。
十五、实时的游戏内建剖析
剖析代码在大部分的软件开发中都是一个常规性的步骤,但在游戏开发中则往往是至关重要的步骤。因为游戏经常性需要监视性能瓶颈和其他可能导致帧率下降的愚蠢错误。当帧率下降时,不通过有效实际测量是无法猜出问题发生在哪儿的。
1.开始考虑细节
这个实时剖析器允许你监控男感兴趣的任意代码点或代码段。只需要在希望剖析的区域开始和结束的时候调用一个函数即可。每个样本中都由一个ProfileBegin和一个ProfileEnd组成,并由一个你选择的标识符来区分。可以使用ProfileBegin("InsertSampleNameHere")和ProfileEnd("InsertSampleNameHere")将想要查看的代码包括进去。
剖析的代价
整体上来说,剖析器用来保持对你样本跟踪的时间总量可以忽略不计,特别当你只要每次监视少量几个点的时候。不幸的是将结果显示在屏幕上的功能,根据实现方法以及文本数量,或许会稍微降低一些你的帧率。
虽然监视代码不会使用很多时间,但还是不要监视太小的代码片断,尤其是那些在一帧内会被执行几百次的代码。否则监视代码可能会使用比目标代码片断更长的时间,并导致实际上更糟的视觉效果。
值得重视的是这个实时剖析器不应该取代传统的剖析器。一个真正的剖析器可以提供给你无法被这个技术所取代的更有价值的信息。也就是说,这个实时剖析器将增强你常常做的剖析工作。可以将这个剖析器看作一种快速但并不优雅的获取有用信息的途径。当你准备获得更精确测量信息时,应该换用更专业的剖析器。
2.剖析器将告诉你什么?
剖析器将在每一帧结束时给你下列信息。你通常会希望将这些信息打印到屏幕或其他的输出设备。
(1)样本点的唯一名称。 (2)在此样本上耗费的平均、最小和最大帧时间比例。 (3)每帧中此样本被调用的次数。 (4)次样本点与其他样本点的关系(父/子)。
剖析器视图智能处理样本并保持对其父子关系的跟踪。例如,如果在你的游戏主循环和游戏主循环的图形绘制例程中都有样本,则父子关系将被自动建立。
结果如下表所示:
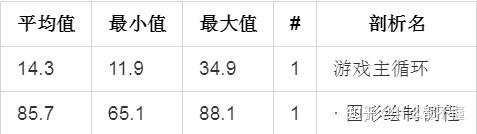
上表显示的结果说明了一些问题
(1)图形绘制例程占用了85.7%的帧率。 (2)除了图形绘制例程之外的其他部分占用了14.3%的帧率。 (3)图形绘制例程在游戏主循环中被调用(通过缩进标示) (4)游戏主循环应该使用100%的帧率,但因为图形绘制例程在游戏主循环中被剖析,因此游戏主循环的帧率要减去图形绘制例程的帧率。 (5)游戏主循环最高使用了34.9%,而平均值只有很低的14.3%,这说明游戏主循环中的一些代码周期性影响帧时间。这些代码也许是人工智能代码或碰撞监测代码,需要增加更多的样本来使用剖析器定位。 (6)游戏主循环和游戏图形例程在每帧中只被调用一次(通过#列标示)。
在增加更多剖析器样本来定位峰值问题后,结果如下表所示。
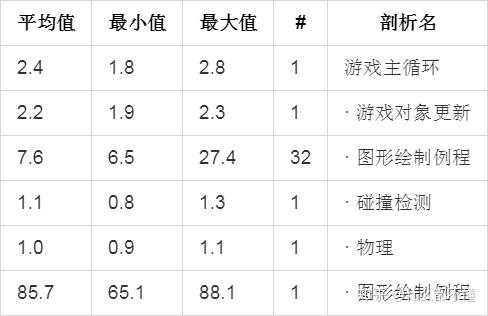
从上表所示结果中,可以发现人工智能修正样本被调用了32次(或许有32个游戏对象需要人工智能)。可以清楚地看出在一些帧中占用27.4%的帧率的人工智能修正是造成峰值的样本。在人工智能修正中应该有一些代码被周期性地调用。也许是那些代码的工作可以被多帧使用,因此造成间隔性的峰值出现。继续增加剖析样本直到确定的代码段被辨别出。使用剖析器能够很容器地跟踪到问题。
3.增加剖析器调用
如前面所述,必须将你希望进行剖析的代码使用ProfileBegin和ProfileEnd包裹起来。你总是应该将你程序的主循环包裹起来,并且在循环末尾调用ProfileDumpOutputToBuffer。ProfileDumpOutputToBuffer将剖析信息格式化文本,并存储到一个文本缓冲区,以使你能在主循环的某处将之显示到屏幕上。
void main{ //在这里初始化代码 ProfileInit(); //你必须在主循环之前调用此函数 while(!ExitGame){ ProfileBegin("Main Loop"); ReadInput(); UpdateGameLogic(); ProfileBegin("Graphics Draw Routine"); RenderScene(); RenderProfileTextBuffer(); //输出最后一帧的剖析信息文本 ProfileEnd("Graphics Draw Routine"); ProfileEnd("Main Loop"); ProfileDumpOutputToBuffer(); //将在下一帧中显示的缓冲区 } }4.剖析器的实现
在一个给定帧中,每个剖析样本需要下列信息:
typedef struct{ bool bValid; //数据是否有效 uint iProfileInstances; //ProfileBegin调用次数 int iOpenProfiles; //没有相匹配ProfileEnd调用ProfileBegin调用次数 char szName[256]; //样本名称 float fStartTime; //当前样本开始时间 float fAccumulator; //帧内所有样本总计 float fChildrenSampleTime; //所有子样本耗时 uint iNumParents; //父样本数 }ProfileSample;我们需要跨越多帧保持的样本历史信息,将在下列结果中被存储:
typedef struct{ bool bValid; //数据是否有效 char szName[256]; //样本名称 float fAve; //每帧的平均时间(百分比) float fMin; //每帧的最小时间(百分比) float fMax; //每帧的最大时间(百分比) }ProfileSampleHistory;为简单和速度考虑,将预分配ProfileSample(s)和ProfileSampleHistory(s)数组。预分配数据使我们在每次采样时不必为分配和释放内存而耗费时间。在任何样本被采样之前,调用ProfileInit来初始化两个数组并记录开始时间。
两个函数被用来获取时间:GetTime和GetElapsedTime。GetTime将以秒的形式返回系统时间(调用时的精确时间)。GetElapsedTime将返回自上一帧完成以来耗费的所有时间(通过1/current_frame_rate计算)。
#define NUM_PROFILE_SAMPLES 50 ProfileSample g_samples[NUM_PROFILES_SAMPLES]; ProfileSampleHistory g_history[NUM_PROFILE_SAMPLES]; float g_startProfile = 0.0f; float g_endProfile = 0.0f; void ProfileInit( void ) { uint i; for( i=0; i= 0) { //记录时间到fChildrenSampleTime(累加) g_samples[parent].fChildrenSampleTime += fEndTime - g_samples[i].fStartTime; } //保存累及样本时间 g_samples[i].fAccumulator += fEndTime - g_samples[i].fStartTime; return } i++; } } void ProfileDumpOutputToBuffer(void) { uint i = 0; g_endProfile = GetTime(); ClearTextBuffer(); PutTextBuffer("Ave : Min : Max : # : Profile Name\n"); PutTextBuffer("----------------------------------\n"); while(i < NUM_PROFILE_SAMPLES && g_samples[i].bValid == TRUE){ uint indent = 0; float sampleTime, percentTime, aveTime, minTime, maxTime; char line[256], name[256], indentedName[256]; char ave[16], min[16], max[16], num[16]; if(g_samples[i].iOpenProfiles < 0){ assert(!"ProfileEnd() called without a ProfileBegin()"); } else if(g_samples[i].iOpenProfiles > 0){ assert(!"ProfileBegin() called without a ProfileEnd()"); } sampleTime = g_samples[i].fAccumulator - g_samples[i].fChildrenSampleTime; percentTime = (sampleTime / (g_endProfile - g_startProfile)) * 100.0f; aveTime = minTime = maxTime = percentTime; //在历史记录中增加新的测量值,并获取平均、最小和最大值 StoreProfileInHistory(g_samples[i].szName, percentTime); GetProfileFromHistory(g_samples[i].szName, &aveTime, &minTime, &maxTime); //格式化数据 sprintf(ave, "%3.1f", aveTime); sprintf(min, "%3.1f", minTime); sprintf(max, "%3.1f", maxTime); sprintf(num, "%3d", g_samples[i].iProfileInstances); strcpy(indentedName, g_samples[i].szName); for(indent=0; indent g_history[i].fMax){ g_history[i].fMax = percent; } else{ g_history[i].fMax = (g_history[i].fMax*oldRatio) + (percent*newRatio); } return; } i++; } if(i < NUM_PROFILE_SAMPLES) { //添加到历史数据 strcpy(g_history[i].szName, name); g_history[i].bValid = TRUE; g_history[i].fAve = g_history[i].fMin = g_history[i].fMax = percent }else { assert(!"Exceeded Max Available Profile Samples!"); } } void GetProfileFromHistory(char* name, f32* ave, f32* min, f32* max) { uint i = 0; while(i < NUM_PROFILE_SAMPLES && g_history[i].bValid == TRUE){ if(strcmp(g_history[i].szName, name) == 0) { //找到一个样本 *ave = g_history[i].fAve; *min = g_history[i].fMin; *max = g_history[i].fMax; return; } i++; } *ave = *min = *max = 0.0f; }知识阅读





软件推荐
更多 >-
 查看
查看皓盘云建最新版下载v9.0 安卓版
53.38MB |商务办公
-
 查看
查看ris云客移动销售系统最新版下载v1.1.25 安卓手机版
42.71M |商务办公
-
 查看
查看粤语翻译帮app下载v1.1.1 安卓版
60.01MB |生活服务
-
 查看
查看人生笔记app官方版下载v1.19.4 安卓版
125.88MB |系统工具
-
 查看
查看萝卜笔记app下载v1.1.6 安卓版
46.29MB |生活服务
-
 查看
查看贯联商户端app下载v6.1.8 安卓版
12.54MB |商务办公
-
 查看
查看jotmo笔记app下载v2.30.0 安卓版
50.06MB |系统工具
-
 查看
查看鑫钜出行共享汽车app下载v1.5.2
44.7M |生活服务
精选栏目
热门推荐


-
1
 联想笔记本电脑清理灰尘详细步骤
联想笔记本电脑清理灰尘详细步骤2022-03-26
-
2
 联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议
联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议2022-03-26
-
3
 神舟bios设置图解教程
神舟bios设置图解教程2022-03-26
-
4
 192.168.1.62登录入口管理网址
192.168.1.62登录入口管理网址2022-03-26
-
5
 ACPI是什么?BIOS中怎么设置ACPI?
ACPI是什么?BIOS中怎么设置ACPI?2022-03-26
-
6
 联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程
联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程2022-03-26
-
7
 联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)
联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)2022-03-26
-
8
 鸿蒙系统能安装vscode吗
鸿蒙系统能安装vscode吗2022-03-26
-
9
 fast路由器设置网址192.168.1.1,falogin.cn密码
fast路由器设置网址192.168.1.1,falogin.cn密码2022-02-15
-
10
 联想笔记本装系统怎么进入PE图文教程
联想笔记本装系统怎么进入PE图文教程2022-02-14





-
1

-
2
机器人战斗竞技场手机版下载v3.71 安卓版
其它手游 -
3
果冻人大乱斗最新版下载v1.1.0 安卓版
其它手游 -
4
王者100刀最新版下载v1.2 安卓版
其它手游 -
5
trueskate真实滑板正版下载v1.5.102 安卓版
其它手游 -
6
矢量跑酷2最新版下载v1.2.1 安卓版
其它手游 -
7
休闲解压合集下载v1.0.0 安卓版
其它手游 -
8
指尖游戏大师最新版下载v4.0.0 安卓版
其它手游 -
9
飞天萌猫下载v3.0.3 安卓版
其它手游 -
10
火柴人越狱大逃脱下载v1.1 安卓版
其它手游