在Java开发环境中运行wordcount程序
发表时间:2022-03-25来源:网络
1 MapReduce介绍
1.1 MapReduce定义MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自身默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
1.2 MapReduce核心思想(1)分布式的运算程序往往需要分成至少2个阶段。
(2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
(3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
(4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
一个完整的MapReducer程序在分布式运行时有三类实例进程:①MrAppMaster:负责整个程序的过程调度以及状态协调。②MapTask:负责Map阶段的整个数据处理流程。
③ReduceTask:负责Reduce阶段的整个数据处理流程。
2 官方WordCount源码
2.1 WordCount案例的实质采用反编译工具反编译源码,发现WordCount案例有Map类、Reduce类和驱动类。且数据的类型是Hadoop自身封装的序列化类型。
2.2 常用数据序列化类型表1-1 常用的数据类型对应的Hadoop数据序列化类型
Java类型Hadoop Writable类型booleanBooleanWritablebyteByteWritableintIntWritablefloatFloatWritablelongLongWritabledoubleDoubleWritableStringTextmapMapWritablearrayArrayWritable2.3 MapReduce编程规范用户编写的程序分成三个部分:Mapper、Reducer和Driver。
1、Mapper阶段
(1)用户自定义的Mapper要继承自己的父类
(2)Mapper的输入数据是KV键值对的形式(KV的类型可以自定义)
(3)Mapper中的业务逻辑写在map()方法中
(4)Mapper的输出数据是KV键值对的形式(KV的类型可以自定义)
(5)map()方法[MapTask进程]对每一个调用一次
2、Reducer阶段
(1)用户自定义的Reducer要继承自己的父类
(2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(3)Reducer的业务逻辑写在reduce()方法中
(4)ReduceTask进程对每一组相同的组调用一次reduce()方法
3、Driver阶段
相当于Yarn集群的客户端,用于提交我们整个程序到yarn集群,提交的是封装了MapReduce程序相关运行参数的job对象
3 Java开发环境配置hadoop
3.1 注意事项1、该Hadoop集群为远程Hadoop集群,我的Hadoop完全分布式集群已配置完毕。
2、Eclipse所在的操作系统为Windows
3、Eclipse所在操作系统已安装JDK
4、Eclipse所在系列为 Eclipse IDE for Java EE
1、eclipse官网下载地址:https://www.eclipse.org/downloads/
2、我下载的是hadoop-2.7.5.tar.gz版本,将其解压到C:\Hadoop\hadoop-2.7.5
3、配置的插件:hadoop-eclipse-plugin-2.6.0.jar、hadoop.dll和winutils.exe文件(有的博客说下载插件要和hadoop版本一模一样,但是我试过之后发现都是下载2.7版本以上的都可以,相差版本不同都行。)
1、增加系统变量HADOOP_HOME,变量值为hadoop-2.7.5.tar.gz压缩包解压到的目录
2、在系统变量中对变量名为PATH的系统变量追加变量值,变量值为%HADOOP_HOME%/bin(注意:添加环境变量最好不要用在中文下的路径)
3、将hadoop-eclipse-plugin-2.6.0.jar拷贝到Eclipse安装目录中dropins文件夹,网上有的文章说该插件版本必须与Hadoop版本一致,但我没有找到2.7.5版本的插件,所以就用2.6.0版本的测试了一下。结果配置好hadoop环境了呀!
若最后没有出现DFS的图标,则hadoop-eclipse-plugin-2.6.0.jar没有识别到,上网一查便知高于2.0版本的插件,需要将插件放在eclipse安装目录中的plugins下,并重启eclipse。
4、打开hadoop-2.7.5的安装目录,打开bin文件夹,复制hadoop.dll和winutils.exe文件,打开目录C:\Windows\System32,将以上两个文件拷贝到该文件夹
5、打开Eclipse,依次点击“Window”→“Preferences”→“Hadoop Map/Reduce”,Hadoop installation directory配置为hadoop-2.7.5.tar.gz压缩包解压目录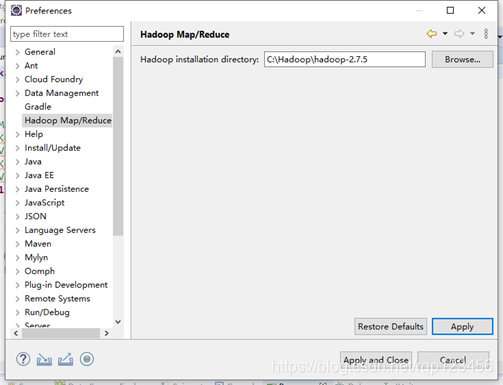
注意:若在Preferences中找不到Hadoop Map/Reduce,则cd到Eclipse安装目录,执行./eclipse -clean,然后重启Eclipse
6、依次点击“Window”→“Show View”→“Other…”→“MapReduce Tools”→“Map/Reduce Locations”
7、在“Map/Reduce Locations”视图中右键“New Hadoop location…”,新建连接
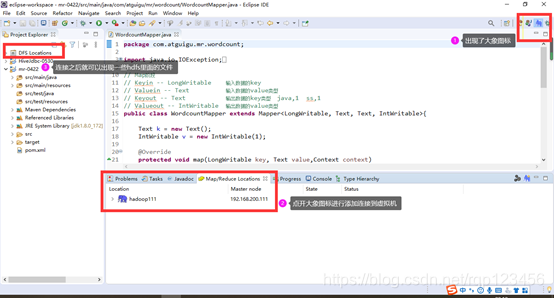
8、弹出这个窗口,就可以添加填写内容了。
(1)Location name:可以任意取名,最好设置为linux的主机名,可以用hostname查看
(2)Map/Reduce(V2) Master下的Host:
方法一:填写远程Hadoop所在虚拟机的IP地址,比如我的是192.168.200.111;
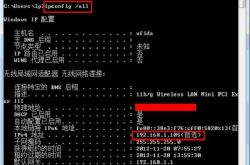
方法二:直接填入其主机名(比如我的是hadoop111),要在相关文件中进行配置:进入目录C:\Windows\System32\drivers\etc,找到hosts文件,打开后加入IP地址与主机名的映射,如下图所示:但是我的这个文件没有权限修改,没办法保存。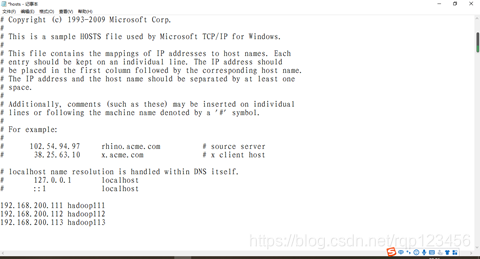
(3)左边的Port:50070是对应的mapred-site.xml的jobtracher地址,如下:
(4)右边的Port:9000对应core-site.xml下的fs.default.name的端口
fs.defaultFS hdfs://hadoop111:9000(5)User name:填写Hadoop所在的操作系统的用户名,我用的是root用户
综上配置内容,配置结果如下图: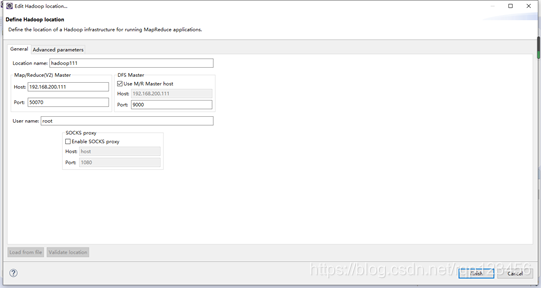
9.接着点击Advanced parameters,从中找到hadoop.tmp.dir,修改为Hadoop集群core-site.xml中配置的值。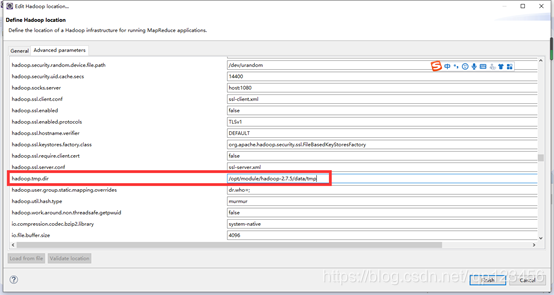
10、接着在Advanced parameters中配置dfs.permssions,修改为false,与Hadoop集群【hdfs-site.xml】中配置的一致;将dfs.replication的值改为3.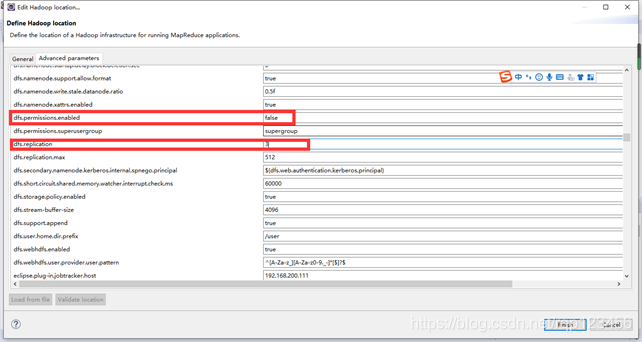
11、配置完成后,一定要在虚拟机上先启动hadoop集群,再点击eclipse右上角的Map/Reduce的大象图标,若左侧Project Explorer中出现如下信息,这表明配置成功,其中tmp、user等目录,是我自己在hdfs中创建出来的,你自己创建会有自己文件和目录。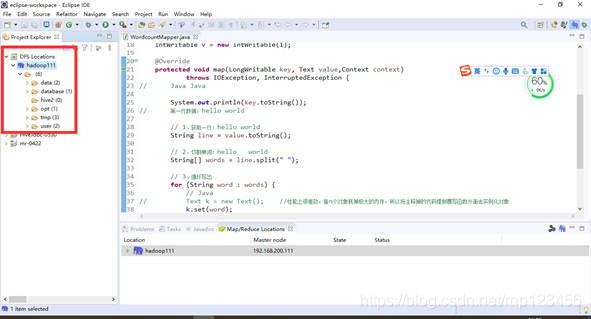
12、右键点击hadf的目录,可以直接通过eclipse将本地文件上传到远程的hdfs中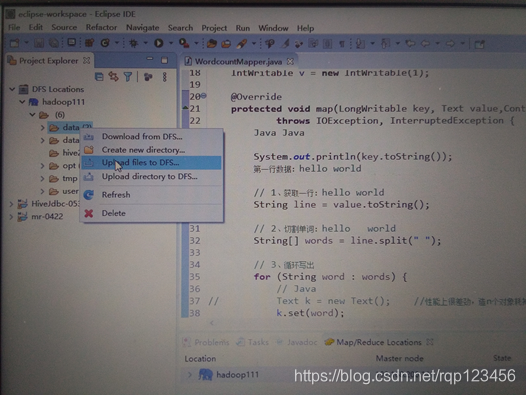
4 WordCountnt案例实操
4.1 需求在给定的文本文件中统计输出每个单词出现的总次数
(1)输入数据:将文件放在我的C:\input\inputword
(2)期望输出数据:
banzhang 2
hao 1
xihuan 1
hadoop 2
hive 1

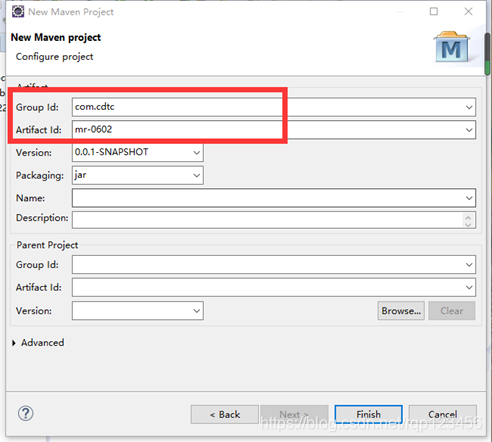
4.3.1 创建maven工程
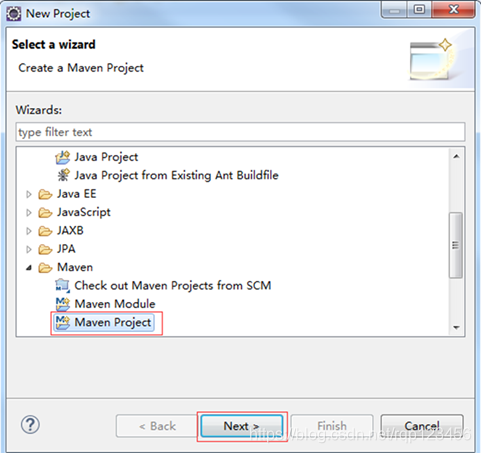
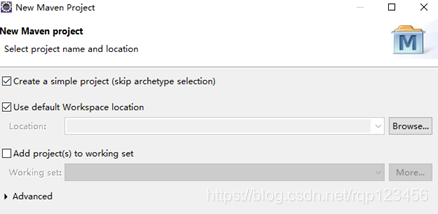
4.3.2 在pom.xml文件中导入依赖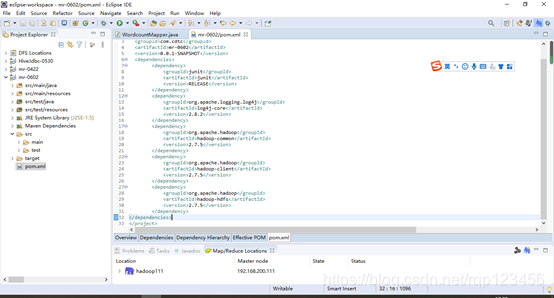
4.3.3 创建文件log4j.properties
在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。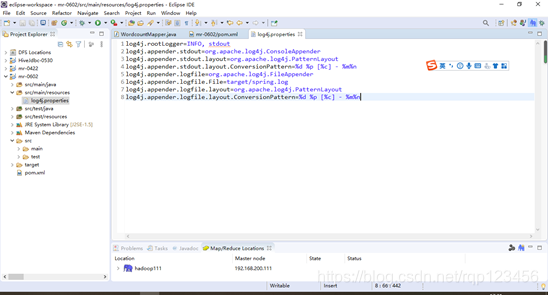
4.4.1 编写Mapper类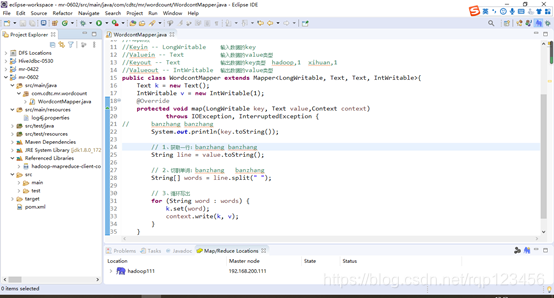
4.4.2 编写Reducer类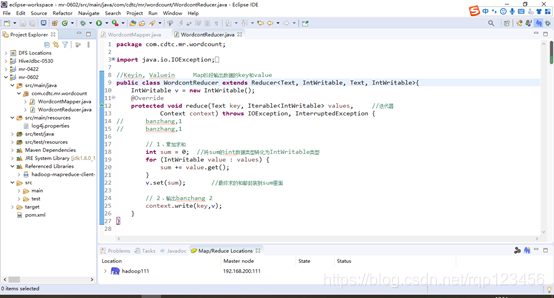

(1)如果电脑系统是win7的就将win7的hadoop jar包解压到非中文路径,并在Windows环境上配置HADOOP_HOME环境变量。如果是电脑win10操作系统,就解压win10的hadoop jar包,并配置HADOOP_HOME环境变量。
注意:win8电脑和win10家庭版操作系统可能有问题,需要重新编译源码或者更改操作系统。
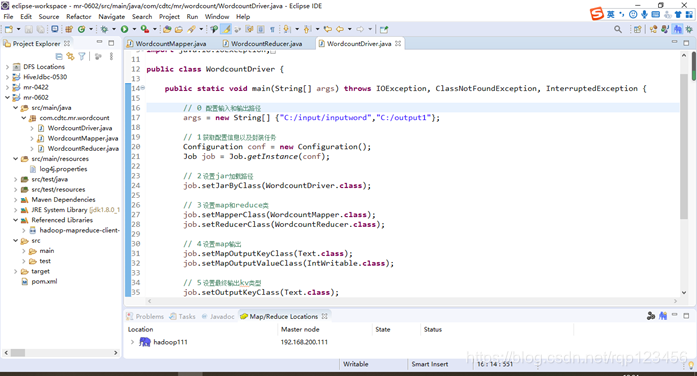
(2)在Eclipse/Idea上运行程序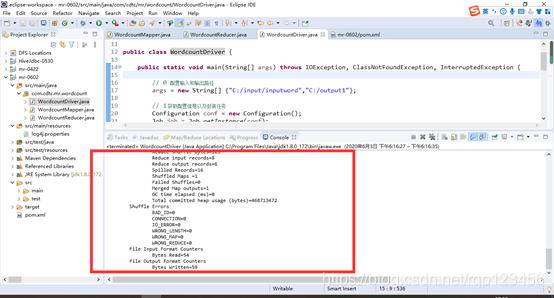


4.6.1 用maven打jar包
需要添加的打包插件依赖,注意:标记红颜色的部分需要替换成自己工程主类,如果项目上显示红叉或pom.xml文件显示也有红叉。先去C:\Users\asus.m2目录下删去所有.lastUpdate文件,再去项目上点击鼠标右键——>maven——>update project即可。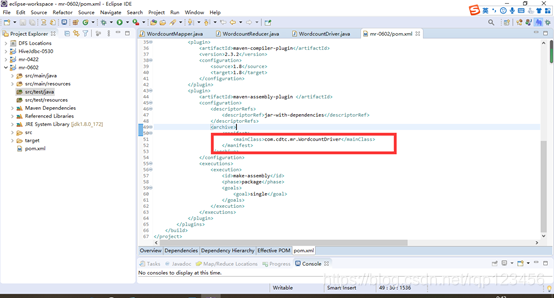
4.6.2 将程序打成jar包,然后拷贝到Hadoop集群
步骤详情:右键->Run as->maven install。等待编译完成就会在项目的target文件夹中生成jar包。如果看不到。在项目上右键-》Refresh,即可看到。修改不带依赖的jar包名称为wc.jar,并拷贝该jar包到Hadoop集群。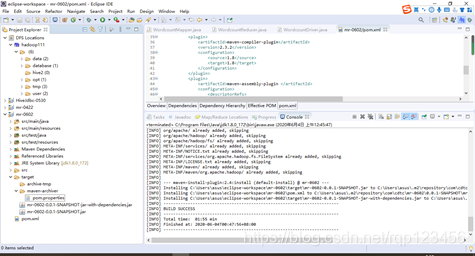
4.6.3 启动集群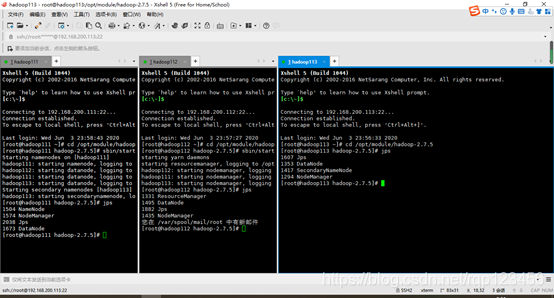
4.6.4 运行WordCount程序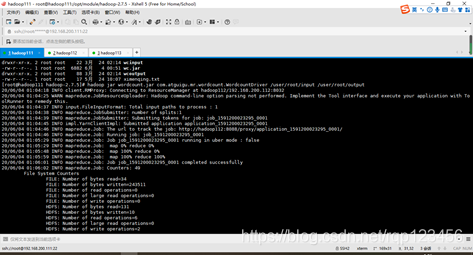
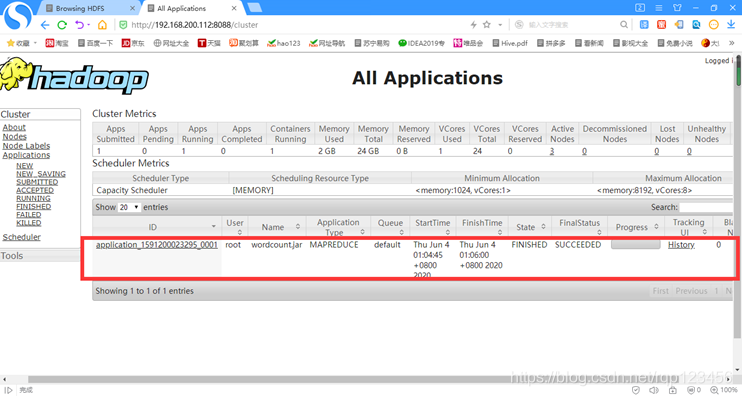
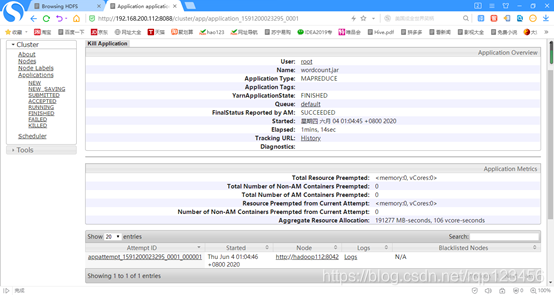
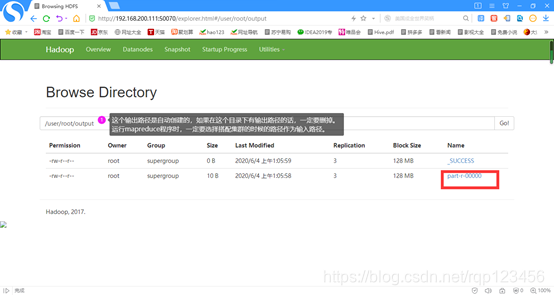
5 小结
首先要熟悉了一下搭建hadoop完全分布式集群配置的全部过程。再运行mapreducer的典型wordcount实例。接下来把配置遇到的错误及解决办法陈列出来,如下:
1、左上角没有发现DFS图标,是因为没有将hadoop-eclipse-plugin-2.6.0.jar放在eclipse安装目录下的plugins下,在重新启动eclipse软件就OK了。
2 、在出现如下图错误时,不要惊慌,开始配置的我还以为是填写MapReduce的port出现了错误,结果是忘记打开虚拟机启动hadoop集群。
3、出现如下图这个错误时,可能是因为配置map/reduce时的环境变量(即hadoop的安装目录设置)发生了变化,只需要重新点一下右上角的大象图标就可以了,为了谨慎起见,还是建议重新启动eclipse软件。
4、在hadoop集群上运行打包成的jar出现错误,是因为主类包名写错了。
上一篇:Java锁分析
下一篇:怎样将日志添加到Java应用程序
知识阅读





软件推荐
更多 >-
 查看
查看皓盘云建最新版下载v9.0 安卓版
53.38MB |商务办公
-
 查看
查看ris云客移动销售系统最新版下载v1.1.25 安卓手机版
42.71M |商务办公
-
 查看
查看粤语翻译帮app下载v1.1.1 安卓版
60.01MB |生活服务
-
 查看
查看人生笔记app官方版下载v1.19.4 安卓版
125.88MB |系统工具
-
 查看
查看萝卜笔记app下载v1.1.6 安卓版
46.29MB |生活服务
-
 查看
查看贯联商户端app下载v6.1.8 安卓版
12.54MB |商务办公
-
 查看
查看jotmo笔记app下载v2.30.0 安卓版
50.06MB |系统工具
-
 查看
查看鑫钜出行共享汽车app下载v1.5.2
44.7M |生活服务
精选栏目
热门推荐


-
1
 联想笔记本电脑清理灰尘详细步骤
联想笔记本电脑清理灰尘详细步骤2022-03-26
-
2
 神舟bios设置图解教程
神舟bios设置图解教程2022-03-26
-
3
 联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议
联想拯救者R7000 2020款清灰教程及对硅脂or导热垫选择参考建议2022-03-26
-
4
 ACPI是什么?BIOS中怎么设置ACPI?
ACPI是什么?BIOS中怎么设置ACPI?2022-03-26
-
5
 联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程
联想ThinkPad笔记本win10改win7系统及BIOS设置图文教程2022-03-26
-
6
 联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)
联想ThinkPad笔记本装win10系统及bios设置教程(附带分区教程)2022-03-26
-
7
 鸿蒙系统能安装vscode吗
鸿蒙系统能安装vscode吗2022-03-26
-
8
 192.168.1.62登录入口管理网址
192.168.1.62登录入口管理网址2022-03-26
-
9
 fast路由器设置网址192.168.1.1,falogin.cn密码
fast路由器设置网址192.168.1.1,falogin.cn密码2022-02-15
-
10
 联想笔记本装系统怎么进入PE图文教程
联想笔记本装系统怎么进入PE图文教程2022-02-14





-
1

-
2
机器人战斗竞技场手机版下载v3.71 安卓版
其它手游 -
3
果冻人大乱斗最新版下载v1.1.0 安卓版
其它手游 -
4
王者100刀最新版下载v1.2 安卓版
其它手游 -
5
trueskate真实滑板正版下载v1.5.102 安卓版
其它手游 -
6
矢量跑酷2最新版下载v1.2.1 安卓版
其它手游 -
7
休闲解压合集下载v1.0.0 安卓版
其它手游 -
8
指尖游戏大师最新版下载v4.0.0 安卓版
其它手游 -
9
飞天萌猫下载v3.0.3 安卓版
其它手游 -
10
火柴人越狱大逃脱下载v1.1 安卓版
其它手游